Covid-19 : Comment optimiser le coût de vos services cloud ?
La crise sanitaire que nous vivons actuellement a mis à l’épreuve bon nombre de nos infrastructures techniques (sites de formation, visio, e-commerce alimentaire...) en occasionnant une surcharge exceptionnelle parfois difficile à supporter. Même s’il est difficile de tirer un bilan définitif, il apparaît que les plateformes et services s’appuyant sur l’élasticité offerte par les fournisseurs de cloud public s’en sont généralement bien mieux tirés que la moyenne. En effet, les pics de connexions violents constatés (x100 chez certaines plateformes de MOOC) sont bien plus faciles à suivre lorsque l’on n’est pas limité par la capacité physique de son propre datacenter, et lorsque les services sont conçus pour se redimensionner dynamiquement. Mais la crise économique sans précédent qui s’annonce va être l’occasion de tirer profit d’un autre avantage du cloud, en ajustant au mieux ses coûts-là aussi grâce à l’élasticité, mais aussi par quelques éléments d’architecture. Voici quelques exemples et conseils pour optimiser au mieux vos services cloud.

Identifier les propriétaires
Le cloud apporte tant de facilité et de promesse d’innovation, que très rapidement chaque société se retrouve confrontée à une multiplication des environnements, projets et ressources parfois difficiles à cartographier. Qui n’a jamais cherché la personne ayant démarré (et oublié) une VM “test” ?
La condition sine qua non pour pouvoir agir sur les coûts est de savoir rattacher les ressources à ses propriétaires (personne physique, projet, business unit, …), sans quoi on se retrouve assez vite dans l’incapacité d’agir.
Pour ce faire dès que possible il convient de mettre en place une gouvernance et des règles de déploiement : comment, par exemple, va-t-on hiérarchiser les projets GCP ? Comment tagger les ressources de différents sous-projets sur un même compte AWS ?
Suivant votre cloud provider, différents outils seront également disponibles pour auditer, et remédier, automatiquement à des informations manquantes. AWS Config peut par exemple automatiquement éteindre toute VM ne portant pas le tag identifiant sa Business Unit de rattachement.
Éteindre & supprimer
Selon votre architecture les services d’infrastructure et spécifiquement les machines virtuelles peuvent représenter une part conséquente de la facture. Sur AWS il est assez trivial d’automatiser l’extinction et le rallumage programmés de ces machines virtuelles et instances RDS à l’aide d’une fonction Lambda (par exemple https://aws.amazon.com/premiumsupport/knowledge-center/start-stop-lambda-cloudwatch/).
Ainsi les serveurs de développement pourront être éteints entre 20h et 7h du matin, ainsi que le week-end, amenant une économie de quasiment 50% (le stockage continuant par exemple d’être facturé)
De plus en plus de services managés proposent également ces fonctionnalités (par exemple RDS et plus récemment Redshift, toujours chez AWS).
Les outils d’Infrastructure as Code (Terraform, Cloudformation, Troposphere, CDK…) sont également clef dans ce contexte. Ils permettent en effet de construire un environnement complet en quelques minutes. Dès lors, si l’on peut recréer facilement, on peut supprimer ce qui n’a pas d’utilité immédiate ( par exemple un projet gelé pour 6 mois).
Redimensionner
En termes d’élasticité toutes les applications ne sont pas logées à la même enseigne, suivant que l’on parle d’une architecture “cloud native” ou plutôt “lift and shift”.
Dans le second cas l’infrastructure est bien souvent composée de machines virtuelles hébergeant des applications monolithiques, et de services de bases de données relationnelles (RDS chez AWS, SQL chez GCP, …) qui ne peuvent pas forcément bénéficier d’autoscaling.
Il convient donc d’examiner les consommations des ressources (CPU, mémoire, disque) de chaque serveur pour identifier les économies potentielles.
Attention à utiliser les bons outils pour cela : Le Trusted Advisor d’AWS, par exemple, se base sur la consommation CPU et réseau des machines virtuelles, mais ne prend pas en compte la consommation mémoire des applications. Il faut donc compléter son analyse avec les métriques adéquates, ou utiliser des outils spécialisés.
Re-architecturer
Différents chemins sont possibles. Le premier consiste la plupart du temps à découpler les composants de l’application afin de les rendre scalables, comme nous l’avons expliqué ici : https://www.ekino.fr/articles/performance-et-scalabilite-des-services-numeriques-a-lheure-du-teletravail. Au-delà de ces étapes une refonte plus en profondeur de l’architecture est possible pour optimiser les ressources. Beaucoup de services managés cloud facturent en effet à la consommation, et donc de façon plus linéaire qu’une infrastructure allumée en permanence.
Ainsi,
- Un cloud-storage GCP peut remplacer dans bien des cas une VM exécutant un Nginx
- API-Gateway et des Lambdas AWS peuvent remplacer un serveur Java
- Une queue AWS Simple Queue Service peut remplacer un serveur RabbitMQ.
C’est évidemment une vision simplifiée (les fonctionnalités ne sont jamais totalement équivalentes) mais suivant votre consommation il est toujours intéressant d’étudier ces opportunités. Au-delà de la réduction de la facture “cloud”, c’est aussi un investissement payant à moyen et long terme sur les coûts humains d’opération.
Étudier les options et prix des services
Pour chacun des services mis en oeuvre, il faut également se poser la question du modèle de facturation et des options activées. Google Cloud Storage propose 4 classes de stockage en fonction des besoins d’accès (Standard, Nearline, Coldline, Archive). Des logs conservés plusieurs années pour des raisons réglementaires peuvent tout à fait être stockés en archive divisant le coût par 6.
AWS Relational Database Service propose des bases de données en haute disponibilité, mais cette option double le prix du service. Est-il nécessaire de l’activer sur un environnement de développement ?
Enfin, toujours chez AWS, les options de prix pour les machines virtuelles EC2 sont nombreuses : standard, instances réservées, saving plan, spot instances … Cette dernière option, particulièrement adaptée pour les traitements batch, apporte aisément des réductions de coûts de 60% et plus.
Pour terminer, il est toujours utile de prêter attention aux coûts de transfert réseau. Suivant que les flux sont intra zone, intra région, publics, et les services qu’ils touchent, les prix varient grandement. Lorsque c’est possible, optimiser l’architecture réseau aura le triple effet de réduire les coûts, d’améliorer les performances ainsi que la sécurité. L’activation des VPC Endpoints (S3 en particulier) chez AWS est un des exemples classiques.
Utiliser des PaaS
AWS, GCP, Azure proposent grâce à leurs très nombreux services une grande flexibilité. Mais cette dernière est souvent au prix d’une complexité technique et organisationnelle.
Pour des projets simples des Platform as a Service telles que Platform.sh ou Clever Cloud sont tout à fait adaptées. Grâce à des environnements standardisés elles sont très rapides à mettre en oeuvre, proposent des workflow de déploiement basés sur git, et masquent une grande partie de la complexité (et donc des coûts) du run.
Pour se lancer
Nous l’avons vu, les pistes à creuser sont nombreuses d’autant que votre écosystème cloud est probablement varié.
L’une des approches les plus efficaces consiste à rassembler en workshop les responsables techniques et product owner de chaque plateforme afin d’analyser ensemble les dépenses. Le cost explorer AWS constitue à ce titre un excellent outil. Il permet en quelques clics de comprendre la répartition des coûts, et si besoin de descendre très en détail (a fortiori si les ressources sont correctement taggées).
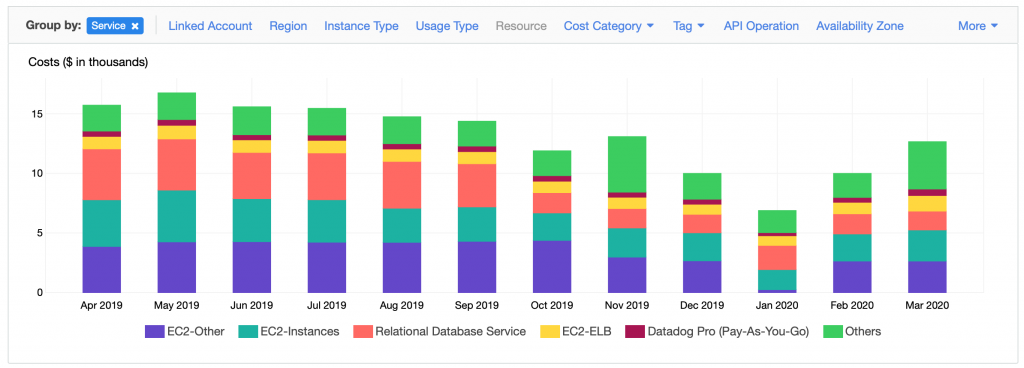
Autour de cet outil, et par petits groupes, on procède à un brainstorming d’une trentaine de minutes pour identifier des pistes d’optimisations en commençant par les plus grandes masses. Les idées sont ensuite partagées et débattues pour échafauder un plan sur lequel chacun s’engage, à la manière d’un sprint planning.
Ainsi, de façon itérative, chaque équipe peut s’emparer du sujet et se responsabiliser sur son impact financier, entamant ainsi une approche “FinOps”.
En conclusion
Les conséquences de cette crise vont être multiples, et sont encore difficiles à dessiner, mais il est évident que les entreprises devront, encore plus qu’hier se concentrer sur la valeur apportée à leurs clients finaux. Les services doivent avoir du sens, être résilients, mais plus que jamais, avoir une dimension d’économie, voir de frugalité.
Il sera intéressant dans les prochains mois d’observer la manière dont les entreprises vont revoir leur stratégie cloud à l’avenir : rationalisation des services pour miser sur les économies d’échelle, investissement sur les technologies “serverless”, focus sur les cloud “souverains”, … beaucoup d’options sont possibles. Mais quoi qu’il en soit le mouvement de fond du cloud reste indissociable de l’agilité requise pour s’en sortir dans les années qui viennent.
Vous avez des questions sur le Cloud ? Un projet ?
Contactez-nousLire plus d’articles
-
5 Minutes read
Covid-19 : Performance et scalabilité des services numériques à l’heure du télétravail massif
Lire la suite -

5 Minutes read
Covid-19 : Réduire les risques tout en continuant sa transformation digitale
Lire la suite -

5 Minutes read
3 étapes pour une expérience client agile post-COVID-19
Lire la suite