Retour sur le 1er jour de conférence de Devoxx 2019 [17/04]
Thomas Carsuzan, Architecte, Lokmane Arkhis, Ingénieur Java confirmé, Stéphane Leclercq, CTO et Fabien Thouraud, Ingénieur Java reviennent sur le 1er jour de conférence de l'édition 2019 de Devoxx.


GraphQL in Java World, let’s go for a dive
Rédacteur : Thomas Carsuzan
Bonne présentation des fonctionnalités de GraphQL et de leur implémentation en Java, manuellement avec Spring, puis avec les auto configurations de Spring :
<dependency>
<groupId>com.graphql-java</groupId>
<artifactId>graphql-spring-boot-starter</artifactId>
<version>5.0.2</version>
</dependency>
Il est assez facile de mettre rapidement en place une solution assez puissante mais on peut très vite se retrouver avec des problèmes de performance car la résolution des sous-entités se fait entité par entité résultant au fameux n+1. Il existe des solutions (type DataLoader) afin de résoudre ces entités en mode batch + caching mais cela complexifie la solution.
Cette solution reste cependant intéressante à étudier selon les cas d’utilisation.
Code disponible sur Github : https://github.com/vladimir-dejanovic/simple-springboot-graphql-mongo-conftalk-demo
ElasticSearch, retour aux sources
Zouheir Cadi, Ryadh Dahimene et Sylvain Wallez
Rédacteur : Lokmane Arkhis
ElasticSearch est un moteur de recherche distribué et full text basé sur la librairie Lucene d’Apache offrant une API Rest.
Pendant ce Hands On Lab, les participants ont eu l’occasion de prendre en main Elastic en abordant des sujets tels que l’indexation (création d’index, de template et d’alias), la recherche (structurée, full-text, multi champs) et les problématiques d’amélioration de pertinence de recherche.
Ils ont aussi pu manipuler des outils tel que Kibana et Logstash et travailler sur un cas d’utilisation de Google Play Store.
Vous pourriez réaborder tous ces sujets en suivant le TP suivant : https://docs.google.com/document/d/1BoZ6t0P2eG3us7AzVbD3mX-kLRSi50oI6KXcvkxUvHE
Toolbox Chaos Engineering du Javaiste
Rédacteurs : Lokmane Arkhis & Stéphane Leclercq
Chaos Engineering est une discipline qui consiste à tester la résilience des systèmes informatiques en simulant des pannes en environnement réel et de vérifier que le système continue à fonctionner.
Durant cette présentation, deux outils connus ont été abordé. Il s’agit de :
- Chaos Monkey créé par Netflix et qui se plug aux applications SpringBoot
- Contient différentes attaques directement dans l’applicatif pour les requêtes (génération de latence, d’exception, ou carrément tuer la requête).
- Peut se mettre sur n’importe quel Spring Bean donc toutes les couches (controllers, services, repositories, etc.).
- Est activé/désactivé via Actuator.
- Globalement très facile à utiliser et dans l’esprit de Spring Boot
- ToxiProxy est de plus bas niveau et un langage agnostic
- Permet de changer le comportement des services distants, par exemple en ajoutant de la latence ou en changeant le statut de retour.
- Utile pour tester le comportement des clients REST
La démo utilisait Hystrix, on aurait préféré quand même resilience4j en 2019 😉
Le code source de la présentation est sur Github
Et pour les lovers des Meetups, il existe aussi une communauté Chaos Engineering sur Paris que vous pourriez rejoindre.
De Java à un exécutable natif : GraalVM et Quarkus changent la donne
Rédacteur : Stéphane Leclercq
Quarkus est une stack Java (on ne parle plus vraiment de framework à ce stade) alternative à Spring Boot dont l’objectif est de redonner un peu plus de joie pendant les développements.

“Je ne vais pas remercier mon MacBook et le jeter par la fenêtre aujourd’hui”
Cela prend la forme d’un archetype maven pour pouvoir monter le squelette du projet (il est également possible d’utiliser Gradle mais il faut monter le projet à la main), et on peut démarrer de suite comme la plupart des scaffolders d’aujourd’hui.
Les features principales de Quarkus sont :
Le live reload
D’entrée de jeu on a du live reload, le principe de la méthode choisie par Quarkus est assez simple : Monter un 2ème classloader, charger l’appli dedans, et les swap. C’est évidemment un peu plus compliqué que cela pour conserver tout ce qui est session etc. mais cela permet de faire des rechargements en dessous de la seconde donc sans casser la concentration du développeur.
En plus du live reload, les stacktraces sont rapportées clairement dans le navigateur lorsqu’il y a une erreur afin d’aider au debug (bien évidemment désactivé en prod ;)). On voit clairement sur toute cette partie l’inspiration du framework Play.
Le live reload est également compatible avec les tests pour pouvoir faire automatiquement des tests d’intégration de son API sur une application live. Assez bluffant sur le papier.
La compilation native
Une fois qu’on est satisfait de nos développements, on peut les compiler en natif avec Graal et SubstrateVM. On passe donc en AOT (Ahead Of Time) Compilation au lieu de JIT (Just In Time) Compilation. Toutes les optimisations sont faites à l’avance. Cela implique donc une compilation assez longue : De 20s à 2 minutes dans les exemples, sûrement bien plus pour une application complexe.
Le résultat est bluffant :
- Un démarrage de l’appli extrêmement rapide : 0.05s incluant les ouvetures de connexion JDBC etc. donc équivalente à une appli déjà “chauffée.
- Une empreinte mémoire beaucoup plus petite : 50Mb au lieu de 200+Mb avec l’overhead de la JVM etc.
ActiveRecord pattern
On connaît Emmanuel pour son travail sur Hibernate depuis de nombreuses années, il nous présente ici PanacheEntity (no comment le nom) qui implémente le pattern ActiveRecord. On quitte donc le grand classique des applis Web Java qui consiste à faire sa couche DAO en dessous de sa couche service et à avoir des domain objects anémiques, pour rejoindre le style plus moderne d’avoir des objets riches qui connaissent leur domaine.
Les extensions
Facilement repérables à l’aide de la cible quarkus:list-extensions et s’ajoutent avec quarkus:add-extension elles permettent d’utiliser déjà de nombreuses librairies de l’écosystème Java. En effet, la compilation native implique l’absence de chargement dynamique de classes et de manipulation de bytecode, donc toutes les librairies ou morceaux de framework se basant fortement dessus ne fonctionnent pas d’entrée de jeu (coucou l’écosystème Spring).
Il y a assez d’extensions disponibles aujourd’hui pour monter des applications solides et on peut croire qu’avec le bourrage de crâne que nous fait RedHat en ce moment, de nombreuses librairies opensource vont sauter sur l’occasion d’être parmi les premières utilisables sur Quarkus.
Un autre avantage est la normalisation : Quarkus simplifie la “dette” liée à la structure du projet en proposant un fichier de configuration unique, un import.sql centralisé pour la gestion du schéma de base de données, etc.
Et alors ?
Globalement RedHat frappe assez fort avec Quarkus et à minima va secouer l’écosystème pour qu’il se modernise, comme l’avait fait Pivotal avec Spring Boot il y a quelques années. Les attentes en termes de developer experience ont changé, et les technologies sont présentes pour pouvoir y répondre, Quarkus ne fait qu’être présent à l’appel.
Temps de démarrage ultra rapides comme Go et confort de développement auquel les devs Javascript sont habitués, tout pour plaire.
Je l’avoue d’entrée : Je suis allé au total à 3 conférences d’Emmanuel sur Quarkus pendant Devoxx. Trois fois la même chose en gros par ailleurs ! Oui, Emmanuel parle pour RedHat de la même façon que Josh Long parle pour Spring, mais au-delà de son experience d’orateur Quarkus semble être digne d’intérêt. Bonus : Il y a déjà beaucoup de détracteurs, ce qui est généralement un bon indicateur de future popularité !
Attention cependant : on est encore sur une stack très immature donc à envoyer avec la plus grande prudence en production et à tester sur des petits projets. Le (relativement) peu d’extensions disponibles, la perte d’InvokeDynamic, le fait que ce soit basé sur une syntaxe Java 8, les PanacheEntity qui n’ont pas encore complètement atterri… font un mix dangereux à surveiller de près avant de plonger tête la première dedans.
Swagger Driven Testing
Rédacteur : Stéphane Leclercq
Le testing d’API est bien souvent réservé aux développeurs via les tests d’intégration avec JCV (article), les outils spécifiques un peu détournés (scénarios Gatling par exemple), ou les consultants techniques qui bricolent dans Postman/Newman. Cela laisse peu de marge de manoeuvre et de possibilités aux consultants non techniques, business analysts, et autres chefs de projets dont les connaissances techniques s’arrêtent au bout de leurs formules excel.
Jean Baptiste propose une solution de tests de non régression d’API grâce à Swagger. Concernant les points forts, l’interface est agréable, simple à maîtriser, s’intègre très facilement dans du CI comme Jenkins, et permet d’avoir ses premiers tests d’API en quelques minutes. L’effet wahou est garanti.
Bien que la solution soit intéressante pour un non tech, elle semble trop limitée pour un développeur : Elle ne permet pas des assertions “intelligentes” (savoir si un champ est une date, un UUID, ignorer une partie de structure, etc.) et, pire, quand elle le peut, il s’agit de valider un schéma donc au final retourner dans la tech avec un outil inférieur aux autres solutions du marché et avec une partie des fonctionnalités cachées derrière une version Pro payante.
A réserver pour les cas d’urgence où il n’y a vraiment aucun test et aucune personne pour pouvoir les faire. Le risque d’avoir les tests swagger qui “passent” alors que l’API a un souci est important par rapport aux autres types d’intégration. Pour faire des tests d’intégration et de non régression d’API au sein de votre appli avec des validateurs intelligents, jetez un oeil du côté de JCV (article).
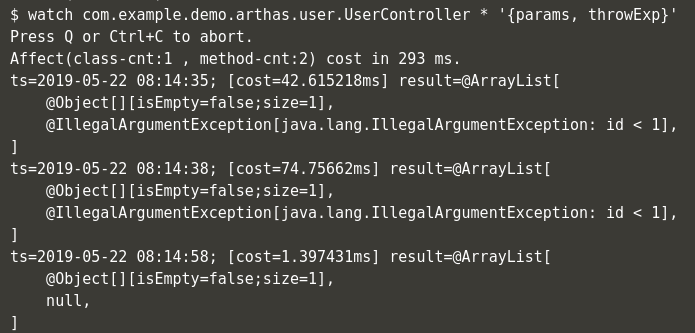
Arthas – Alibaba Java Diagnostic Tool
Rédacteur : Fabien Thouraud
Alibaba, géant chinois de l’e-commerce, organise chaque année un jour spécial de promotions sur l’ensemble de sa plateforme le 11 novembre. En 2018, sur cette unique journée, 1 milliard de CA en moins de 2 minutes pour un total de 30 milliards et 1 milliard de colis à expédier.
Et tous les services nécessaires à la plateforme tournent sur des Tomcat embarquant plusieurs applications. Afin de faciliter le debug en production (oui oui !), ils ont mis au point Arthas, un outil ligne de commande capable de s’attacher à une JVM en cours d’exécution. Outre les fonctionnalités d’analyse qu’il offre (dashboard, thread, erreurs), il est possible de décompiler des classes ; les modifier et les déployer à chaud. Il est également possible de monitorer une ligne de code spécifique, filtrer les erreurs et même rejouer des appels avec un même jeu de paramètres.
Java keeps throttling up!
Rédacteur : Thomas Carsuzan
A leur habitude, José et Rémi were on Fire !
Présentation du projet Loom : Peut-être vue comme des threads lights, les “continuations” peuvent “run” and “yield” (Pause) laissant la place à l’exécution d’une autre “continuation“.On peut donc avoir plusieurs “continuation” par thread. Ce n’est plus le system mais la JVM qui va s’occuper du scheduling.
Pour passer d’un système de Thread + Lock aux continuations, il faut réécrire le code !
Pour éviter ce souci on peut utiliser les “fiber”. La jvm détecte que l’exécution d’un morceau de code se fait dans une “fiber” et va automatiquement faire des “yield” sur les appels bloquants. Pour cela, l’ensemble des appels bloquants présents dans la lib standard java (java.io, java.nio, Thread.sleep, java.util.concurrent., … ) ont dû être réécrits. Ainsi, il est toujours possible de faire des appels bloquants dans une Fiber sans être bloquant!
Le gros avantage des continuations/fiber sur nos implémentations réactives, c’est de pouvoir continuer de coder comme avant sans l’ajout des wrapper types Flux<>/Mono<>/… et de la complexité qui s’ensuit (implémentation et tests).
Concernant l’ensemble des features utilisant des ThreadLocal, ça ne fonctionnera pas car la fiber peut s’exécuter sur des threads différents
La JVM fera donc des FiberLocal automatiquement. Mais comme potentiellement on aura plus de fiber (le but étant de pouvoir en avoir plus que des threads) il faudra faire attention à la mémoire.
Concernant les transactions avec Spring qui utilisent ces ThreadLocal, cela devrait donc bien se passer mais restons prudents.
Au passage, Rémi précise de toujours faire du ReentrantLock au lieu de synchronize car c’est plus performant lorsque plusieurs Thread s’arrêtent sur le synchronize.
Thread.currentThread devra utiliser Fiber.currentThread
Comme la plupart des développements sur les continuations concernent la pile, le projet Loom contient aussi la feature de “tail call optimization”, qui permet d’éviter d’allouer une nouvelle frame sur la pile lorsque cet appel est fait à la fin de la méthode appelante (Très efficace sur les appels récursifs).
Un test a été fait avec Jetty en remplaçant les threads par des fibers et les gains de performances seraient assez intéressants.
Des exemples sont disponibles sur le github de Rémi Forax :
https://github.com/forax/loom-fiber
Présentation du projet Amber
Il s’agit de pouvoir faire du pattern matching (switch on steroids) en Java. Ceux qui font du Scala ou Kotlin sont déjà familiers à cet feature du langage.
Tout commence par la définition de type “record” au lieu du type “class” (https://cr.openjdk.java.net/~briangoetz/amber/datum.html), ainsi nous avons l’équivalent des data class de Kotlin mais immutables !
Ex : record User (String name, String email)
Pas le droit d’ajouter des champs hors du constructeur, car sinon ils ne sont pas dans le equals (contrairement à Kotlin). La génération des méthodes se fait directement dans la JVM et non pas dans le bytecode.
Le pattern matching se fait avec le mot clé “switch” qui pourra maintenant retourner une valeur. Le mot clé “break” n’est plus requis avec l’arrow syntax (il ne s’agit pas de lambda !). Afin de retourner une valeur, il faudra utiliser le mot clé “break-with …” afin de ne pas “return” de la méthode appelante.
Sur les enums et les sealed interface, il ne sera plus nécessaire de mettre “default” si toutes les valeurs sont utilisées.
Enfin, il y a aussi le type inférence mais cela nécessite la définition d’une nouvelle variable :
Object x = getValue();
If(x instanceof String newvar) log.info(newvar.length)
https://github.com/forax/amber-demo
Comprendre et maîtriser la performance de vos applications Spark
Rédacteur : Thomas Carsuzan
En passant rapidement sur les concepts des applications Spark, Raphaël est rapidement entré dans le vif du sujet. Grâce à son expérience, il a pu apporter de nombreuses réponses et présenter plusieurs outils afin de comprendre, réaliser, et monitorer ses applications Spark.
Voici quelques key points :
Les datasets sont les plus récents dans Spark et sont souvent à prioriser. Une application Spark peut tourner sur différents types de cluster :
- yarn
- mesos
- kubernetes
- local
- standalone
Sur AWS EMR c’est sur yarn.
Il est possible de lancer une application spark de 2 manières :
- Avec spark-submit en mode client (le driver est exécuté sur la machine qui fait le submit). ATTENTION, les logs du driver ne seront pas consolidés dans le reporting => ne pas utiliser en production
- En mode cluster (le driver est exécuté sur le cluster)
Tips : spark-submit est capable de lancer un jar hébergé sur un repo maven => lui passer un fake jar car ce paramètre reste requis.
Monitoring
Spark utilise Log4j et les logs sont stockés sur chaque machine du cluster avant d’être consolidés par Yarn.
Il est recommandé d’ajouter le nom du thread et les milliseconds au pattern de logging de Spark afin de pouvoir analyser correctement un job.
Durant l’exécution d’un job, les events sont streamés (web ui) et une fois le job terminé, il est encore possible de voir ces infos (history server capable de relire l’event log)
Pour s’assurer de la performance d’un job, il faut s’assurer que le shuffle write soit égal au shuffle read de l’étape suivante sinon c’est que le cluster a travaillé pour rien.
Vérifier aussi que la quantité de données lues par un executor est assez uniforme entre les executors, sinon on a un process qui travaille plus que les autres et on parallélise mal.
Web ui est un des meilleurs outils de diagnostic.
Il est possible d’ajouter des listeners d’event supplémentaires simplement via la configuration ou via le code. Voici 2 listeners intéressants :
- Sparklint diagnostic (https://github.com/groupon/sparklint)
- Sparklens (https://github.com/qubole/sparklens)
Sparklint permet de voir facilement si notre job est bien fait bien, bien parallélisé.
Les plateaux jaunes nous disent aussi si on utilise tout le cpu ou non et donc si le fait d’ajouter plus de ressources cpu servira ou non.
Sparklens est très intéressant car il permet d’estimer ce qu’il se passera si on augmentait le nombre d’exécuteurs.
Metrics
Lorsque vous faites du Spark Streaming, il est important d’activer les metrics sinon il est impossible d’avoir des informations sur la performance de l’application car le job n’a pas de fin (Dropwizard Metrics Library fonctionne de base avec plusieurs types de “sink”). Attention : Besoin de recompiler les sinks sur notre version Spark sinon il peut y avoir des soucis.
Spark Catalyst Optimizer
Voici les optimisations importantes réalisées par Catalyst :
Il commence par une phase d’analyse (vérifie que les champs demandés existent)
Ensuite il optimise (heuristiques prouvés et appliqués dans le bon sens)
- Existe-t-il une partition de type Hive pour ce filtre (c’est juste un dossier avec les fichiers partitionnés (ie year=1996)) ? Si on filtre sur une partition, Spark sait aller chercher uniquement les fichiers de ce dossier
- Push down : Spark sait ne ramener qu’une partie des données si filtrées (ne marche pas avec tous les types de fichiers)
- Projection push down : Si je ne veux que certaines colonnes, Spark sait aussi ne lire que ces colonnes
Il est possible d’accéder aux plans d’exécution : Explain sur un dataset ou sur via la web ui. Afin de voir le code généré par Janino, il faut faire un explain codegen.
Comment choisir le type de fichier à utiliser avec Spark ? Compressé ou non ? Splitable ?
Si ces fichiers ne sont utilisés que par Spark, Parquet est souvent le meilleur format, avec Avro. Sinon ça dépend. Le seul moyen de savoir est souvent de tester et nous sommes aussi souvent constraints par le format d’origine de ces fichiers.
L’association Parquet + snappy est souvent un bon choix, par contre il faut éviter le format “json” et “xml” qui ne sont pas du tout efficaces.
En augmentant le block size de la compression lz4, on consomme un peu plus de mémoire mais les gains sont vraiment intéressants.
Il est important de noter qu’un fichier compressé n’est pas splittable par Hadoop et ne peut donc être parallélisé. Seul bzip2 permet de splitter un fichier compressé.
Spark est capable d’inférer le schéma à partir d’un jeu de données. Cependant cela prend du temps et n’est donc pas à activer en production. Par contre, il est intéressant de le faire la première fois pour récupérer le schéma et l’écrire en dur dans le code ensuite.
Pimp up your Spring Batch en streaming avec Spring Cloud Data Flow et Kafka !
Rédacteur : Thomas Carsuzan
Au cours de cette session, Adriana a présenté une alternative à un ETL Spring batch en créant un pipeline Spring cloud dataflow permettant à partir d’un batch spring de lecture en amont, d’envoyer des events Kafka vers des sinks Spring cloud task streams.