Retour sur le 2ème jour de conférence de Devoxx 2019 [18/04]
Marie Bonnissent & David Porcheron, Ingénieurs Java séniors, Thomas Carsuzan & Léo Millon Architectes et Stéphane Leclercq, CTO reviennent sur le 2ème jour de conférence de l'édition 2019 de Devoxx.




Modern Java: Change is the Only Constant
Java a beaucoup changé ces dernières années, le nouveau modèle devenant plus flexible, plus sûr, et plus facile à maintenir.
Parmi les projets à suivre, le projet Amber s’efforce de réduire le boilerplate pour augmenter la productivité des développeurs. Il est notamment à l’origine de l’inférence de type introduite dans Java10, de l’utilisation du switch comme une expression pour le rendre moins verbeux, ou encore des “records” qui permettent de définir plus facilement des classes de données.
Le projet Loom quant à lui introduit la notion de “fibers”, notion proche des threads mais en beaucoup plus léger car les fibers peuvent partager le même thread.
Les tests en charge en milieu hostile, ou comment tout faire au dernier moment et s’en sortir comme un prince
Super présentation de Guillaume Corré! Durant ce talk, Guillaume nous a fourni la méthodologie à suivre lorsque l’on souhaite mettre en place des tests de charges, plutôt que de se jeter tête baissée dans leur implémentation/mise en place.
Tout d’abord il faut définir un scénario. Quel parcours tester ? Pour cela Gatling fournit un recorder web afin de gagner du temps.
Ensuite il faut définir les critères d’acceptance : temps de réponse ? Nombre d’erreurs ?
Ne pas utiliser la moyenne mais les centiles sinon on ne voit pas les cas à la marge qui peuvent être très loins de la moyenne !
Enfin il faut définir un profil d’injection : ie : 100 utilisateurs puis 100 nouveaux qui arrivent chaque secondes pendant 5 minutes. Cela dépend bien sûr de votre projet et des performances que vous devez atteindre.
On se retrouve avec la formule suivante :
GIVEN mon profil WHEN scenario THEN Critères d’acceptance
Ensuite nous devons choisir quel sera le stand de tir :
- Ma machine en local ?
- Une machine sur le data center ?
- Une machine sur un data center dans une autre région/continent ?
- n machines ?
Tout dépend de ce que nous devons tester mais il est important de bien penser à la réalité de ce qui est mesuré (latence réseau, bande passante, …)
Avec une machine, on peut déjà faire énormément de choses. Traffic Control ‘tc’ sur linux permet par exemple de simuler des lenteurs réseau.
Une fois le stand de tir défini, il faut sélectionner la mitrailleuse.
Sur AWS, les instances C3 et C5 offrent un très bon rapport Cpu/Bande passante. Toujours penser à vérifier que les images (AMI) utilisées soit HVM (Hardware virtualization), ce qui est le cas de l’ami amazon linux.
Pour visualiser ses résultats il est possible d’utiliser prometheus/grafana.
Cependant, quand on souhaite utiliser une machine comme mitrailleuse Gatling, il est important que la machine soit configurée pour: Tcp fin wait! Tcp fin timeout, limite du nombre de ports, …). Heureusement toutes ces optimisations sont disponible sur le github de Guillaume :
https://github.com/notdryft/hostile-territory
20 choses à connaître quand on fait du Kubernetes
Pendant cette conférence, Alain Regnier nous a fait part de plusieurs années d’expérience avec Kubernetes et des tips/choses qu’il aurait aimé savoir avant de se lancer :
- Tout d’abord, il peut être utile de définir des alias autour de kubectl car les commandes sont longues et pas toujours évidentes à se souvenir. Il est possible de choisir le format de retour de kubectl : –output=jsonpath, -oyaml
- Dans un fichier de ressource Kubernetes, on peut définir plusieurs ressources séparées par —
- Pensez à activer l’autocompletion de kubectl, ainsi il est capable de compléter le nom des ressources avec tab en inspectant le cluster.
- Pour accéder à la console web : kubectl proxy –port 8080
‘kubectl top’ est similaire à la commande top et permet de voir l’utilisation des ressources du cluster : kubectl top nodes, kubectl top pods, … - Pour pouvoir monitorer son cluster, il faut utiliser heapster ou metrics-server.
- Utilisez le port forward pour accéder à un pod. Cela marche aussi sur un service (choisira un pod pour vous). Pensez à définir des limites et des garanties d’utilisation de ressources pour vos pods. Attention si la limite de mémoire est atteint, le pod sera killed! Ce n’est pas le cas avec une limite cpu. C’est aussi à partir de ces requêtes que Kubernetes décide sur quel noeud sera déployé un pod. Il est important de noter que les pods sans request seront les premiers à être killed !
- Utilisez les ressources quota et limit range par namespace afin d’éviter que le namespace de dev prenne toutes les ressources de celui de qualif par exemple.
- Il peut aussi être intéressant de jeter un oeil aux ‘daemonset’ (1 pod sur chaque node) et aux ‘statefulset’ (ordre des replica conservé et disque réattaché ex:db) au lieu des replicaset.
- Utilisez les probes et healthcheck : Readiness et liveness probes : http command, … Cela permet d’éviter d’envoyer du trafic vers un container qui n’a pas encore complètement démarré! On peut aussi jouer avec le initialdelayseconds.
- Kubectl exec permet de lancer une commande/shell directement sur un container. Pensez à vérifier que vos cluster Kubernetes managés sont multi-zones (Les masters seront sur différentes zones ce qui permet de limiter les risques de perte d’un cluster)
Cubetto, Thymio… Kezako ?
Dans cette conférence, Xavier Bourguignon nous présente les outils utilisés lors de Devoxx4Kids pour initier les enfants au code.
La présentation commence avec Robot Turtles, un jeu de plateau dans lequel on essaie de déplacer une tortue jusqu’au diamant de sa couleur. Pour bouger la tortue, le joueur doit décider à l’avance d’une suite d’actions (tourner à gauche, tourner à droite, avancer, etc) qui s’exécutent les unes à la suite des autres.
Dans le même genre, mais avec plus de matériel, Cubetto est un petit robot en bois qui se déplace sur un tapis quadrillé à partir d’instructions de déplacement placées sur un panneau de commande. Cubetto introduit de manière amusante le concept de fonction avec la possibilité de réutiliser une suite d’actions à plusieurs endroits dans le parcours.
Un autre robot, plus avancé celui-ci : Thymio possède des capteurs et un gyroscope et peut déclencher des actions en fonction d’événements (tourner à gauche si il y a un obstacle sur la droite par exemple).
Scratch ensuite est un langage de programmation qui se manipule via une interface graphique, il est très complet et permet d’aborder tous les concepts de base de la programmation.
Enfin, plus dans le domaine de l’électronique cette fois-ci, Makey Makey est un dispositif d’émulation de clavier qui vous permettra de transformer une banane ou une feuille de papier en manette de jeux.
Authentification/Autorisation dans les microservices
Vivien Maleze & Florian Garcia
Cette session nous propose un tour d’horizon et retour d’expérience sur les méthodes populaires d’authentification et d’autorisation dans un contexte d’architecture microservices.
Les prérequis sont d’abord listés :
- SSO (Single Sign On)
- Fédération d’identité (type LDAP)
- Social Login (Google, Facebook, etc.)
- Gestion de rôles
- Facilité d’administration
- Bonne intégration avec langages et frameworks classiques : Spring, Dotnet, Nodejs
- Coûts (maintenance ou saas/licence)
Plusieurs solutions plus ou moins payantes répondant à ces problématiques sont sur le marché, dont Okta, Auth0, Keycloak…
La suite de la présentation rentre dans les détails de 3 méthodes populaires ici résumées :
- Basic : La plus simple, mais vulnérable et pas d’intégration avec les tiers. A bannir en 2019 !
- OpenID : Un “nouveau” standard avec OAuth2 répondant à quasi tous les besoins. Les inconvénients sont la complexité et l’obligation d’utiliser HTTPS (bien que je ne trouve pas ce dernier point un inconvénient, il peut poser problème pour les archis ou SI trop legacy…)
- SAML : Le standard “ancien” ayant l’avantage d’être encore aujourd’hui plus mature qu’OpenID et plus facilement accepté dans les vieilles DSI. Tout aussi complexe qu’OpenID, il est également très verbeux.
En conclusion, il paraît évident d’après ce retour d’expérience de partir sur OpenID si le projet le permet, SAML sinon.
PostgreSQL is the new NoSQL
Ce talk a été présenté par Laurent Doguin, Head of Developer Relations chez Clever Cloud.

Laurent a commencé par une petite rétrospective des problématiques de base de données. Dans le passé, lorsque nous avions besoin de plus de stockage ou de puissance CPU, la solution privilégiée était régulièrement verticale, c’est-à-dire augmenter la puissance et la taille des machines. Lors de ces phases d’évolution de machine, on devait couper l’accès à la base de données et on attendait plusieurs heures (en fonction de la taille de la base) pour pouvoir migrer l’ensemble des données. Or, avec l’explosion d’Internet et les besoins de scalabilité, de traitement de données de masse et de livraisons en continu, les solutions d’expansion verticale ont laissé la place aux solutions d’expansion horizontale, comme par exemple paralléliser les traitements sur plusieurs machines ou pouvoir échelonner le nombre de machine en fonction de la charge.
Les RDBMS classiques n’étaient donc pas calibrées pour ces nouveaux challenges, à savoir pas assez flexibles sur la structure de données (pas de multimodel, schéma stricte), pas de scalabilité horizontale et pas résilientes aux cas d’erreur.
D’où l’arrivée des bases de données NoSQL. Et qui dit base de données NoSQL, dit théorème CAP pour Consistency (= la donnée à un instant t doit être la même à n’importe quel moment, ce qui demande une gestion des transactions lors de la persistance de la donnée), Availability (= le système doit être dispo 100% du temps) et Partioning (= avoir un système de cluster avec des noeuds indépendants pour éviter une répercussion des problèmes entre chaque noeuds, extrêmement important dans un système distribué). Le concept de théorème CAP est très important dans le monde du BigData, l’idée est de peser le pour et le contre de chacune des composantes CAP sachant qu’on ne peut pas avoir l’ensemble des trois aspects dans une seule et unique solution de base de données NoSQL.
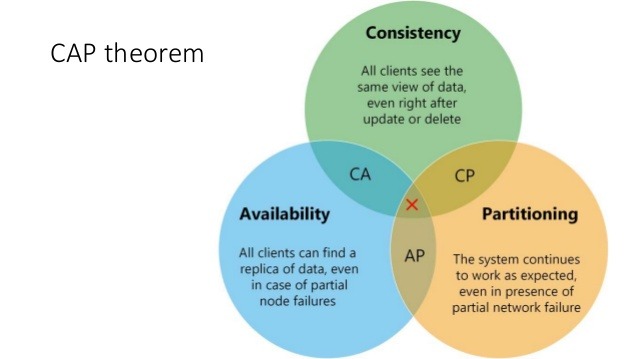
Bon c’est très bien tout ça mais quel est le rapport avec PostgreSQL ?
PostgreSQL est une base de données relationnelle, qui va donc avec son lot de contraintes et de sémantique strict mais elle propose plusieurs fonctionnalités intéressantes qu’on pourrait qualifié de fonctionnalités “NoSQL”, comme par exemple :
- Avoir la possibilité de faire du “schemaless” avec le type jsonb. Ce type n’est autre que du json au format binaire qui a donc déjà été parsé, ce qui permet un requêtage plus rapide mais un insert plus lent. La force de ce type de colonne est la possibilité de pouvoir le requêter de façon fine en SQL comme n’importe quelle autre colonne traditionnelle. Exemple : la colonne jsonb info qui contient le payload suivant :
'{ "customer": "John Doe" }'si on execute la requête suivante :SELECT info -> 'customer'AS customercela donne le résultat suivant : “John Doe” (pour plus d’informations https://www.postgresql.org/docs/11/functions-json.html). En plus du système de requêtage, il est possible de poser des indexes sur les attributs du jsonb, ce qui permet d’améliorer les performances des requêtes au sein du jsonb. - Pour requêter un large set de données, il est possible depuis la version 10 de PostgreSQL d’ajouter des paramètres à la base de données pour définir le nombre maximum de “worker” en parallèle et le nombre maximum de “worker” par connexion à la base pour permettre d’exécuter une requête en parallèle grâce à l’utilisation intensive du CPU.
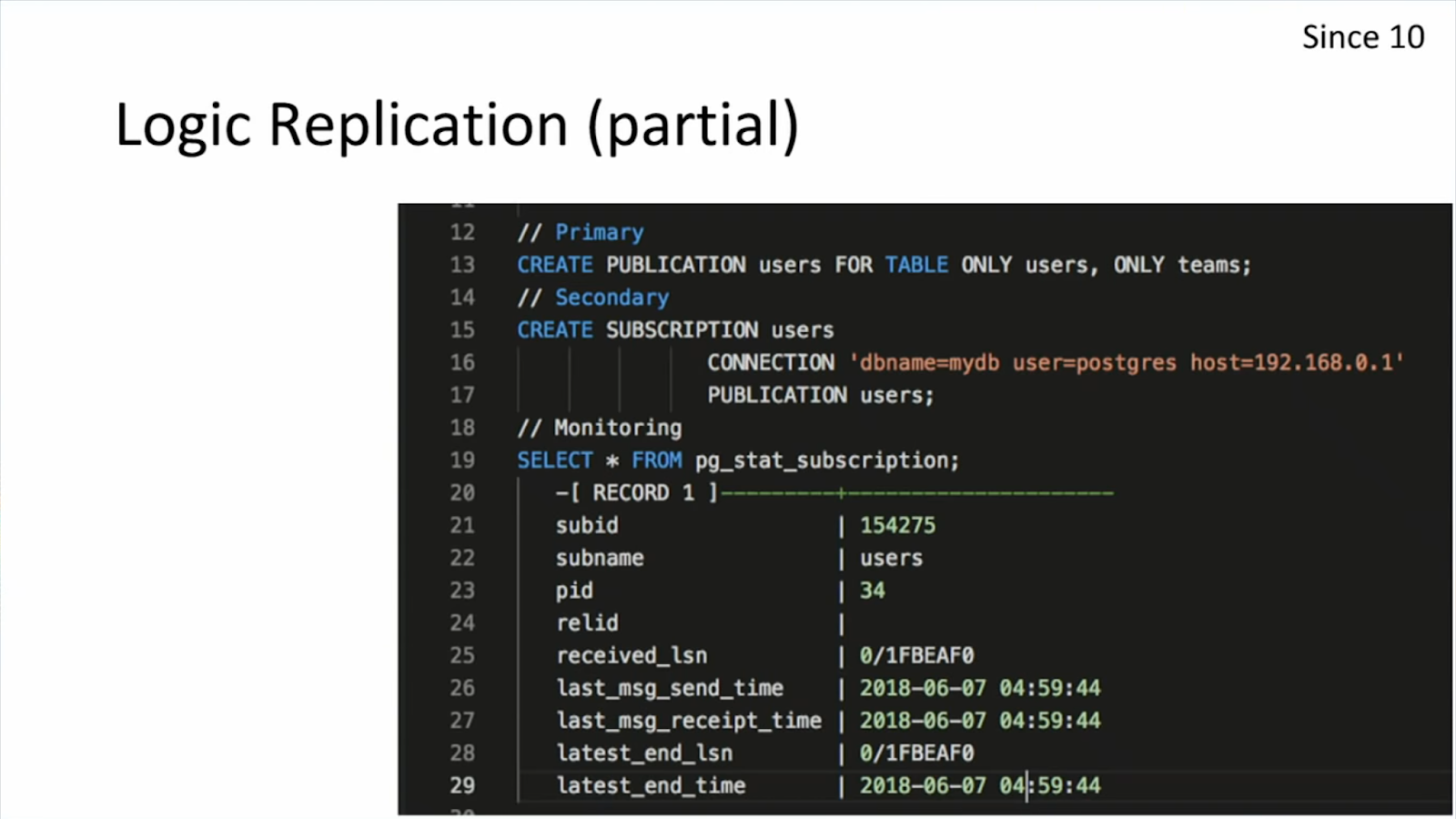
- Au sujet de la scalabilité, PostgreSQL propose plusieurs techniques de réplication :
Master/slave classique, avec lequel on est obligé de s’occuper de séparer les requêtes d’écriture sur le master et les requêtes de lecture entre les différents slaves. Pour simplifier ce système, l’outils pgpool permet de faire cette séparation de requêtes. Réplication logique : avec un système de publication/subscription il est possible de définir une ou plusieurs tables comme publication et une ou plusieurs souscriptions. Pour chaque activité sur les tables en publication, un événement est envoyé aux subscriptions de façon transactionnelle. Cela permet par exemple, de définir un groupe d’utilisateurs qui ont accès à ce réplica de données qui peuvent le requêter comme bon leur semble sans pour autant impacter les performances des tables de production.
- Foreign Data Wrapper : Ce système permet l’interopérabilité avec les autres types de base de données (avoir la possibilité de se connecter à une autre base pour requêter ou écrire de la donnée). Il est possible aussi de faire du “Table Sharding”, c’est à dire en fonction d’un critère discriminant, on peut décider de diviser une table en sous-table (https://pgdash.io/blog/postgres-11-sharding.html). Et donc pour pousser le concept un peu plus loin, il est possible de faire du table sharding entre plusieurs bases de données PostgreSQL grâce au Foreign Data Wrapper qui va lire et écrire sur plusieurs bases distantes en parallèles.
- Temporal function : faire de la timeseries sur un créneau pour de l’analyse de query.
- Avoir la possibilité de faire du réactif avec R2DBC. Laurent nous a fait une petite démo du retry-backoff à chaud lors d’un upgrade d’instance de bdd et c’était plutôt intéressant. L’idée étant qu’au lieu de partir en erreur lamentablement lorsque la base est down, avec la programmation réactive au niveau des appels en base on peut définir un traitement dans la partie onError pour uniquement loggé un message et faire du retry, par exemple toutes les 10 sec, pour rejouer la requête en question.
Evidemment ça ne remplacera pas une vraie solution NoSQL comme Hadoop ou MongoDB mais ces features ont le mérite d’exister et permettent d’avoir une partie des avantages du NoSQL (flexibilité du modèle, scalabilité et performance) dans le monde relationnel.
Kafka – the asynchronous microservices runtime for state, scale and performance
Dans cette session en anglais, Neil Avery nous parle des principes fondamentaux de Kafka et comment ils peuvent résoudre certains des problèmes architecturaux que nous rencontrons sur les microservices.
Une hypothèse que Neil avance dès le début de son talk est que la donnée au repos dans les bases de données classiques n’est pas vraiment de la donnée car elle est mutable, elle ne tient pas compte du facteur “temps” (à quel moment je suis / j’étais dans cet état). La conclusion logique étant que seul un état dirigé par les évènements a du sens. Pas sûr que ce raccourci mental soit valide mais soit.
Cela lui permet de poser les principes d’architecture de Kafka : Au lieu d’avoir un grand nombre de bases de données et d’event streams différents et hétérogènes (RDBMS, NoSQL, sessions, queues, etc.) on met Kafka au centre de l’architecture avec lequel tous les microservices communiquent lorsqu’ils veulent lire ou écrire sur les données, sous forme d’événements. Les streams deviennent votre modèle de données !
Les bénéfices sont classiques et assez connus : Rejeu, rollback, audit… en termes de conception c’est au plus proche du DDD donc attractif. Concernant l’infrastructure il y a des patterns dans Kafka qui permettent de “simuler” des paradigmes connus (métriques en time series, clé/valeur, etc.)
Globalement c’était une présentation d’introduction des concepts de Kafka d’un point de vue assez “avant-vente” (mettez Kafka au milieu de tout et tout se passera bien !). Je suis resté sur ma faim face à un Neil Avery qui semblait très fatigué, et qui n’a à priori pas pu dérouler toute sa présentation (le résumé sur le site de Devoxx allait plus loin).
Du réactif au service du pneu connecté
Cette présentation nous a exposé les nouvelles contraintes engendrées par la volonté, chez Michelin, de recueillir les données remontées par les capteurs (température, pression) intégrés dans leurs pneus connectés. En effet, les exigences de rapidité de traitement (500 req/sec minimum) d’un tel volume de données n’étaient pas atteignables avec la plateforme existante et le besoin de l’adapter devenait inévitable.
C’est ainsi que l’architecture a dû évoluer d’une API monolithe (en Grails) “synchrone” vers un découpage en microservices couplé à une approche réactive (“asynchrone”) en utilisant Vert.x et RxJava 2 ainsi que Kafka pour assurer l’échange des messages entre chaque brique.
Ces choix ont visiblement très bien répondu à la problématique et les démonstrations effectuées lors de cette présentation (contexte simplifié mais très représentatif des problématiques rencontrées) ont permi de se projeter et apprécier les explications.
Ce succès vient tout de même avec quelques points d’attention :
- Tout découpage en micro-services permet de résoudre des problématiques du monolithe mais apporte également son lot de nouvelles problématiques (dénormalisation, traçabilité des échanges, etc.)
- Il y a eu une longue montée en compétences des développeurs juniors de l’équipe sur les concepts de la programmation “asynchrone”/fonctionnelle.
Déploiement de vos secrets applicatifs : Hashicorp Vault et la livraison en continu
Dans le cadre d’applications connectées à d’autres systèmes (à des bases de données, des services nécessitant une authentification, etc.) il est presque systématiquement nécessaire de devoir gérer des identifiants, secrets, certificats et toute autre information sensible.
Cette présentation a très justement rappelé qu’il est indispensable de retirer toute existence, apparition d’information de ce type dans le code source (versionnée et peut être même publique) afin de la déporter dans des outils dédiés (password manager et autres).
Ensuite, la démarche consistait à présenter une solution de déploiement de l’application qui embarque son propre “vault” (coffre numérique contenant les accès nécessaires au bon fonctionnement de l’application). L’idée est intéressante dans le sens où les informations sont au plus proche de l’application et positionnées dans un coffre sécurisé “à la volée” (à l’aide de certificats et tokens à usage unique puis renouvelables). Nous obtenons pour chaque JVM déployée un token unique en session (renouvelable toutes les X minutes) pour son coffre unique.
Cette approche est alléchante mais à condition de se placer dans un contexte très particulier, car un point très important peut très vite vous décourager de choisir cette solution : 1 JVM = 1 token (en session) = 1 vault => si vous éteignez la JVM, le token en session est perdu et il est maintenant impossible d’accéder au coffre.
Il faut donc considérer quelques points importants lors de la mise en place :
- Adapter la chaîne de déploiement pour générer des coffres à la volée.
- Vous ne pouvez pas redémarrer votre JVM, il faut refaire un déploiement avec à nouveau une génération de coffre et token associé.
- Si vous utilisez des stratégies d’auto-scaling pour votre application, à moins d’être capable d’intégrer la génération d’un coffre + token (comme lors du déploiement) dans la procédure de démarrage d’une nouvelle instance, vous ne pourrez pas démarrer votre JVM.
En résumé, cette solution est intéressante mais il faut bien anticiper les limites imposées par cette pratique avant de se lancer car chaque “livrable” de votre application est usage immédiat (expiration du token pour la première ouverture du coffre) et unique (une fois le token en session perdue, le coffre n’est plus utilisable).
Lire plus d’articles
-

11 Minutes read
Retour sur le 1er jour de conférence de Devoxx 2019 [17/04]
Lire la suite