Une solution d'APM dans la suite Elastic
La suite Elastic n’est plus à présenter avec le célèbre triptyque Elasticsearch, Logstash et Kibana permettant d’indexer les logs applicatifs et de les consulter avec des options de filtrage et de recherche avancée.

La suite Elastic n’est plus à présenter avec le célèbre triptyque Elasticsearch, Logstash et Kibana permettant d’indexer les logs applicatifs et de les consulter avec des options de filtrage et de recherche avancée.
La compagnie Elastic a fait un premier pas dans la collecte de données plus techniques avec leur suite d’agents Beats. Ces derniers se présentent sous la forme d’exécutables permettant de récupérer des métriques système, des données d’audit ou encore sonder la disponibilité d’un service.
Plus récemment, une solution d’APM (Application Performance Management) a fait son entrée dans le panel de services proposés et c’est ce que nous allons découvrir à travers cet article.
Application Performance Management / Monitoring
D’après son nom, un APM permet de suivre les performances d’une ou plusieurs applications en fonctionnement. Ainsi, les caractéristiques principales que l’on peut attendre d’une solution d’APM sont les suivantes :
- Récolte de métriques système (charge CPU, mémoire disponible et utilisée, I/O disque ou réseau, …),
- Récolte de métriques plus spécifiques au contexte (JVM, container, infrastructure cloud, …),
- Visualisation des transactions applicatives (dans le cas d’une API, de la requête HTTP entrante jusqu’à sa réponse) avec un suivi des étapes intermédiaires (autrement appelé “span”),
- Analyse des temps de réponse (min, max, moyenne, etc.),
- Visualisation rapide des erreurs survenant sur l’application,
- Définition d’alertes sur des évènements particuliers (augmentation du temps de réponse, nombre de messages dans une file, …),
- Visualisation des logs au moins en cas d’erreur.
D’après ces éléments, on remarque qu’une telle solution doit nous permettre de surveiller la santé de notre application et d’être éventuellement alertés lorsque celle-ci se dégrade. Elle doit également nous permettre d’analyser les comportements anormaux tels que des réponses HTTP non prévues et d’avoir tous les éléments sous la main pour essayer de comprendre la cause (logs avec stacktrace, métriques système et JVM, …).
Il est pour cela important que notre système inclue un mécanisme de corrélation de logs c’est-à-dire que le déclencheur de notre code permet d’identifier toutes les étapes jusqu’à la réponse à cet évènement. Cela passe généralement par l’apposition d’un identifiant rattaché à chaque trace que produira l’application à la suite du déclencheur.
Elastic APM
La solution que nous allons décrire ici est proposée par la société Elastic et s’intègre donc parfaitement dans la fameuse suite ELK (Elasticsearch, Logstash et Kibana). Afin d’ajouter la fonctionnalité APM à Kibana (disponible depuis la version 6.3), nous devons démarrer un serveur APM dédié que l’on peut trouver sous 3 formats : image Docker, binaire à installer ou bien en SaaS.
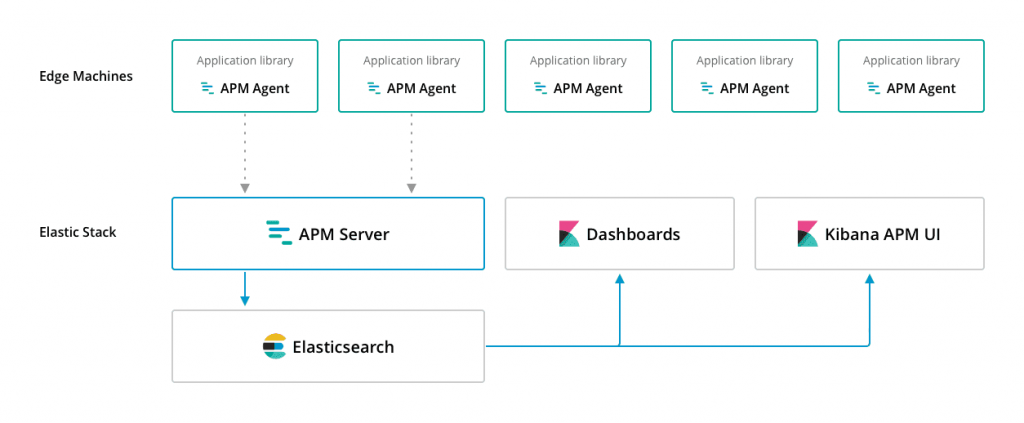
Source : https://www.elastic.co/guide/en/apm/get-started/6.5/overview.html
Comme l’illustre le schéma ci-dessus, ce serveur est directement connecté à l’instance d’Elasticsearch (par défaut, sur le port 9200) et il sert à faire le lien avec l’agent permettant de recueillir les informations de l’application (d’autres solutions comme Datadog ou New Relic utilisent un système similaire). Pour une application Java, l’agent se présente sous la forme d’un JAR à activer par une option de la ligne de commande. Elastic en propose pour tous les langages suivants : Java, .NET, Node.js, Go, Python et Ruby.
JAVA_OPS="${JAVA_OPS} -javaagent:elastic-apm-agent.jar"
JAVA_OPS="${JAVA_OPS} -Delastic.apm.service_name=sample-app-${INFO_ENVIRONMENT}-${INFO_CLASSIFIER}"
JAVA_OPS="${JAVA_OPS} -Delastic.apm.server_urls=${APM_SERVER_HOST}"
JAVA_OPS="${JAVA_OPS} -Delastic.apm.secret_token="
JAVA_OPS="${JAVA_OPS} -Delastic.apm.enable_log_correlation=true"
JAVA_OPS="${JAVA_OPS} -Delastic.apm.application_packages=com.ekino.fth"Les deux premières lignes activent l’agent et nomment l’application. La troisième permet de lier l’agent au serveur d’APM. Le secret_token permet de s’assurer que seules les applications avec le bon token peuvent envoyer des données. Il s’agit simplement d’une chaîne de caractères renseignée côté serveur APM et agent. La cinquième ligne permet d’activer le tracing des requêtes (désactivé par défaut). Enfin, on indique à l’APM le package de base de notre application. La liste des options est décrite ici.
Les métriques collectées concernent la JVM :
- Mémoire heap max, utilisée et garantie,
- Mémoire non-heap max, utilisée et garantie,
- Le nombre de threads,
- Le nombre de fois où le GC est passé, le temps cumulé de collection du GC et la mémoire approximative allouée dans la heap.
- On retrouve également quelques métriques système :
- Le pourcentage de temps d’activité du processeur normalisé par rapport au nombre de coeurs,
- Le pourcentage de temps passé par le processeur depuis le dernier événement,
- La mémoire totale disponible,
- La mémoire libre (inclus le cache et buffer sur Linux mais pas Windows),
- La mémoire virtuelle dédiée au processus.
Enfin, on trouve quelques métriques applicatives : - La durée des transactions,
- Le nombre de transactions ayant créé une “span”,
- La durée des “span”.
Les métriques de la JVM sont indispensables et celles concernant les transactions et “span” peuvent être utiles à l’élaboration de graphiques spécifiques et doivent de toute manière servir pour l’affichage de la section APM de Kibana que nous découvrirons plus en détail. En revanche, les métriques systèmes semblent un peu limitées ; la documentation stipulant que pour avoir des métriques plus intéressantes nous pouvons nous tourner vers leur solution Metricbeat.
Je ne détaillerai pas cette solution ici, mais il faut savoir que si l’on souhaite recueillir des métriques plus variées (AWS, Docker, Kubernetes, Kafka, système, …) il faut soit installer le composant Metricbeat directement sur l’image Docker de votre application ou bien sur la machine l’hébergeant ou encore dans un service dédié. La première solution alourdit votre image tandis que la seconde demande un coût supplémentaire.
D’ailleurs, pour mes tests, je ne me suis intéressé qu’à la version Docker des composants Elastic pour des questions pratiques. Les services Elasticsearch, Logstash et Kibana ne demandent pas de configuration particulière ; je ne vais donc pas m’attarder sur eux.
Le serveur d’APM est également simple à configurer, car il cherche Elasticsearch sur l’URL elasticsearch:9200 par défaut ce qui est exactement ce qui nous arrange. Le cas contraire, il faut ajouter l’option suivante au démarrage du conteneur : output.elasticsearch.hosts=["elasticsearch:9200"].
Enfin, pour tester le composant mesurant les temps d’arrêt et de fonctionnement des services (nommé Heartbeat), il est nécessaire de faire un peu de configuration :
heartbeat:
monitors:
- type: http
schedule: '@every 5s'
urls: ["${API_HEALTHCHECK_URL}"]
check:
request:
method: GET
response:
status: 200
json:
- description: check status is UP
condition:
equals:
status: UPPour plus de détails, je vous invite à vous rendre sur mon répertoire GitHub contenant toutes les sources de l’application Java, le fichier docker-compose.yml et les configurations nécessaires. Vous pourrez également y trouver le profil de test JMeter que j’ai utilisé pour obtenir des données intéressantes dans Kibana.
L’image suivante est un lien vers mon répertoire GitHub : https://github.com/fthouraud/elastic-apm-test

Et tout ça dans Kibana !
L’avantage de cette solution est qu’elle s’intègre directement dans Kibana dédié jusqu’ici aux logs applicatifs et à la visualisation. Les composants Beats sont également intégrés mais sans lien direct avec la section APM. Pour l’intégration, rien de plus simple : sur la page d’accueil, un bouton “Add APM” permet de suivre les étapes de configuration qui demeurent assez simples.
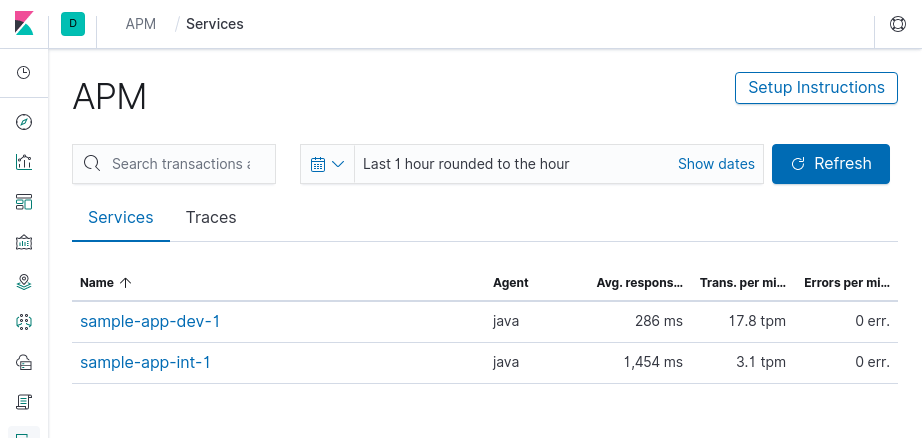
La page d’accueil de cette section affiche la liste des applications pour lesquelles le serveur a reçu des informations avec un résumé du temps de réponse moyen, du nombre de transactions par minute et du nombre d’erreurs par minute.
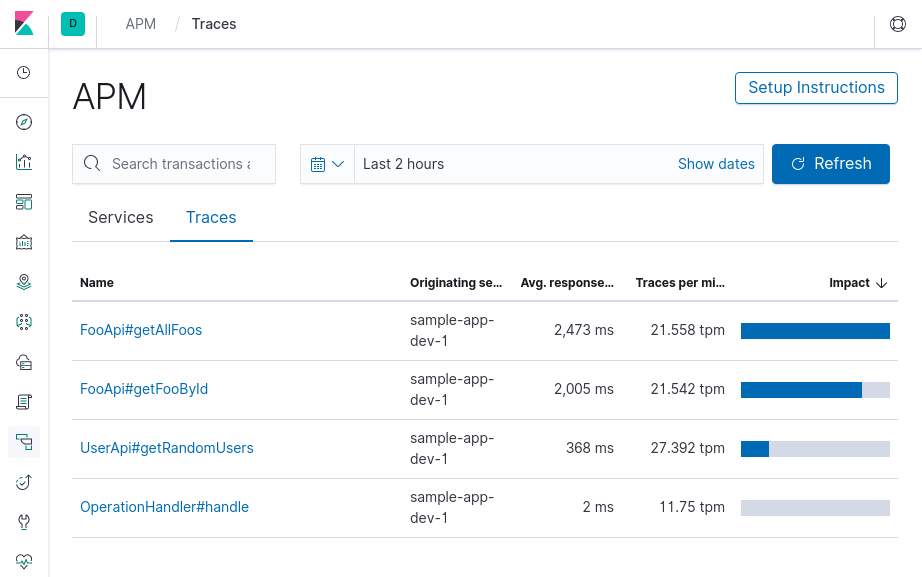
L’onglet “traces” quant à lui nous liste l’ensemble des appels reçus pour nos services avec son lot de statistiques.
Pour accéder au détail d’un service, il suffit de cliquer sur son nom dans la liste du premier onglet (“services”). On retrouve alors dans le premier onglet nommé “transactions” l’ensemble des appels enregistrés pour ce service avec leurs statistiques, mais aussi deux graphiques retranscrivant la durée des transactions pour l’un et les requêtes par minute catégorisées par statut HTTP pour l’autre. À l’exception de ces deux graphiques, on ne se cache pas qu’il est semblable à l’écran “traces” décrit juste au-dessus…
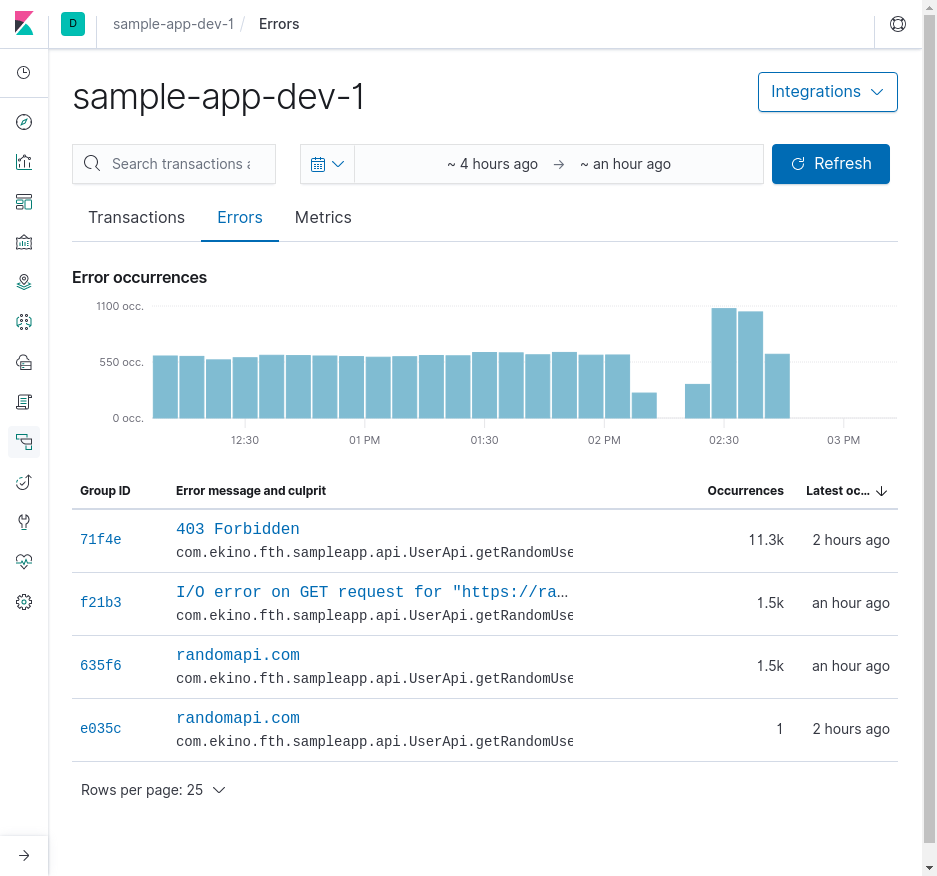
L’onglet suivant, “errors”, nous présente sans surprise la liste des erreurs survenues sur nos services. Elles sont regroupées automatiquement par Elasticsearch, dénombrées et le temps depuis la dernière occurrence est décompté. Un histogramme agrémente cet écran.
Enfin, l’onglet des métriques permet de suivre la santé du système mais il n’offre au final que peu de relevés … En effet, les 3 premiers graphiques sont ceux des onglets “transactions” et “errors”. À ceux-là s’ajoutent un graphique sur l’utilisation du processeur et un second sur l’usage de la mémoire système.
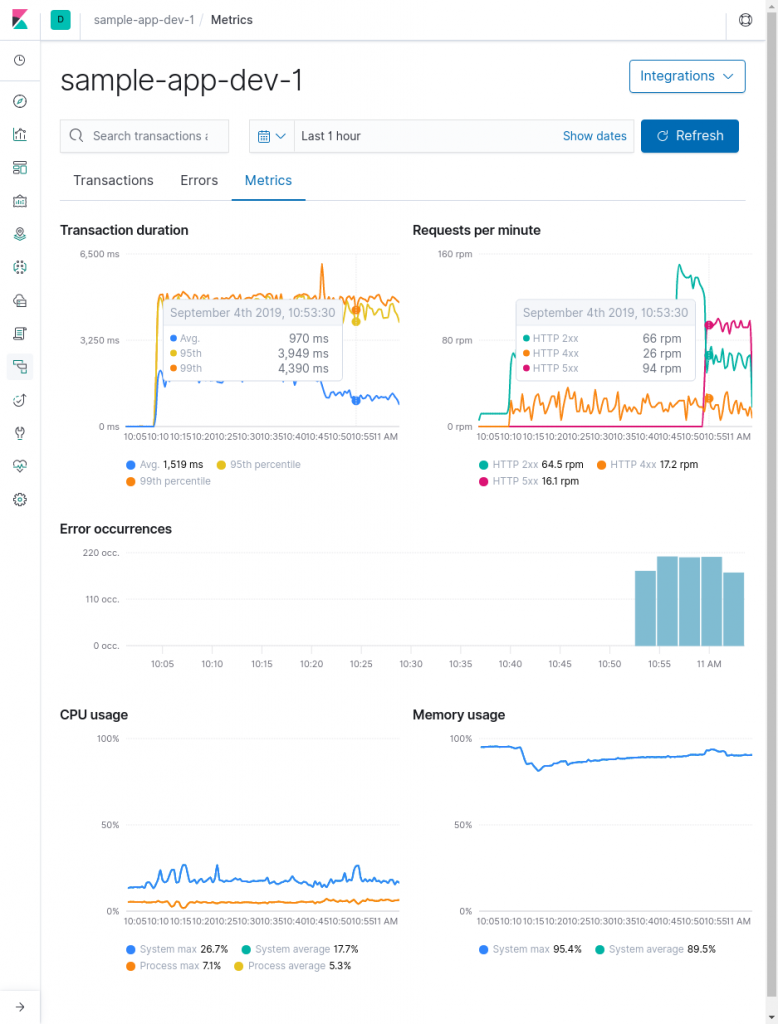
L’agent est capable de fournir des métriques sur la JVM mais celles-ci ne sont pas visibles, à moins de créer une visualisation dédiée qui se retrouvera dans une page spécifique et non plus du côté APM. Ce choix est assez frustrant puisqu’on imagine facilement être amené à consulter les métriques de la JVM en cas d’erreur de type “OutOfMemory” par exemple.
Pour obtenir du détail sur un type de transaction en particulier, il suffit encore une fois de cliquer sur son nom dans la liste de l’onglet “transactions”. On retrouve une énième fois les graphiques sur les transactions et les requêtes auxquels s’ajoute un histogramme sur la distribution des transactions dans le temps.
En revanche, il ne semble pas possible de voir la liste réelle des transactions du type choisi puisque cet écran affiche simplement un exemple de transaction (“transaction sample”). Ce choix semble lui aussi délicat puisque le but même d’un APM est de pouvoir suivre les performances de l’application et il me semble intéressant de pouvoir parcourir soi-même les transactions afin de pouvoir mettre en évidence des pistes d’amélioration.
On notera tout de même que la transaction est découpée en “span” permettant d’étudier les actions majeures intervenant dans une transaction. Ainsi, nous voyons ici que la transaction a effectué un appel en base de données qui a duré 70 µs. Il est possible d’obtenir un peu de détail comme la requête SQL et le type de base de données ou la pile d’appels et l’URL pour un appel HTTP externe.
On remarque que les lignes provenant de notre code source sont automatiquement mises en avant et les lignes intermédiaires sont cachées, mais peuvent être consultées au besoin.
Les autres onglets proposent du détail plus ou moins intéressant. Pour les plus, on retiendra l’onglet “HTTP” décrivant la requête. Quant aux moins, les onglets “Agent” et “URL” semblent particulièrement inutiles ; le premier donnant juste la version de l’agent et le second décompose l’URL affichée juste au-dessus.
L’ouverture d’une transaction en erreur affichera sensiblement le même résultat à l’exception que la chronologie des étapes de la transaction est remplacée par la pile d’appels de l’erreur. Il s’agit toujours d’une transaction d’exemple prise parmi le lot d’erreurs du même type, mais nous avons cette fois un lien permettant de rejoindre la recherche de logs pré-filtrée pour cibler toutes ces erreurs. L’idée est intéressante, mais n’est disponible que sur l’index de logs de l’APM et n’offre donc pas la possibilité de corréler cette erreur avec les logs applicatifs.
Un produit encore jeune
Elastic étoffe encore sa gamme de produits et nous propose cette fois-ci un APM s’intégrant directement avec la suite ELK. Du côté des bons points, il faut reconnaître qu’il est intéressant de pouvoir effectuer le suivi complet de son application du même endroit, au lieu d’avoir une suite ELK d’un côté et Datadog ou New Relic de l’autre. D’un point de vue esthétique, Kibana et son APM s’inscrivent dans l’air du temps avec un design sobre et quelques touches de couleurs pour apporter de la lisibilité.
En revanche, je trouve que la présentation des données relevées par l’agent n’est pas toujours très pertinente. Par exemple, il me semble primordial pour une application Java d’afficher la mémoire JVM et le GC mais celles-ci ne sont disponibles qu’en les créant soi-même dans l’espace “Visualisation” et donc hors de l’espace APM. Cela empêche de faire le lien rapide entre une erreur et l’état du service à ce même instant. Par ailleurs, les graphiques de la durée des transactions et des transactions par minute se retrouvent au moins sur 3 écrans ce qui me semble peut-être excessif.
On notera aussi qu’il est nécessaire de s’en remettre à un autre outil, Metricbeat, lorsque l’on souhaite s’interfacer avec un outil externe (PostgreSQL, Nginx, AWS, …). Datadog utilise cette solution également mais s’intègre aussi directement avec l’API CloudWatch pour AWS. Concernant Elastic APM, en revanche, la liste des intégrations est pour l’instant bien trop faible avec pour AWS la seule collecte des métriques EC2 ; Azure et GCP n’étant même pas mentionnés.
Pour autant, l’agent bénéficie d’une meilleure intégration. Il s’interface sans soucis avec bon nombre de clients HTTP permettant ainsi de récupérer des informations sur les appels faits y compris avec le corps de la requête (désactivé par défaut). Il est également compatible avec les serveurs d’application majeurs du monde Java : il supporte JMS, Quartz et des frameworks web tels que Spring, JAX-RS/WS, JSF et l’API Servlet à partir de sa version 3.
Je pense que cette solution, bien qu’encore incomplète, peut correspondre à certains clients bénéficiant déjà d’une stack ELK mais n’ayant pas forcément la place pour le budget d’un APM dont le prix est souvent assez élevé. De plus, cette solution est gratuite en l’état et une licence n’est nécessaire que lorsqu’on souhaite bénéficier d’un service de “machine learning” qui analyse nos logs pour identifier des comportements anormaux ou bien pouvoir créer des alertes. Il peut donc s’agir d’un premier pas vers une solution APM mais il ne semble pas pertinent de passer d’une solution d’APM dédiée à l’implémentation proposée par Elastic car il manquera quelques fonctionnalités importantes.