23/05/2019
Retour sur le Spring One Tour par Lukas Cardot
Lukas Cardot, Ingénieur Java revient sur le Spring One Tour et plus particulièrement sur les avantages de la programmation réactive.


Spring réactif et ses performances
Les possibilités offertes par la programmation web réactive avec WebFlux sont très belles et vendent du rêve, mais les performances d’une telle application se comparent-elles avec l’expérimenté Spring MVC ? Nous allons observer et tenter d’analyser les performances offertes par ces deux types d’application web.
Cet article ayant pour but d’observer les avantages de la programmation réactive, et non d’expliquer ses concepts, la petite introduction qui suit n’a pas prétention d’expliquer exhaustivement ce sujet. Si vous avez déjà de bonnes connaissances sur la programmation réactive et sur WebFlux, n’hésitez pas à vous rendre directement à la section Spring MVC vs WebFlux.
La programmation réactive en 2 mots
La programmation réactive est un modèle de programmation basé sur la réaction face au changement, à la disponibilité et à la transformation, comme une interface utilisateur réagissant à une touche, ou un driver de base de données réagissant à une modification.
Un autre mécanisme important associé au Réactif est la gestion du backpressure. Le backpressure est l’habileté du consommateur à notifier le producteur que le taux d’émissions est trop élevé. Dans du code impératif et non-bloquant, un backpressure naturel sera appliqué en forçant l’appelant à attendre une réponse. Dans du code non-bloquant, il devient essentiel qu’un appelant puisse gérer lui-même la quantité d’évènements qu’il peut traiter afin qu’une production rapide d’évènements ne submerge pas un consommateur lent.
Reactive Streams est une spécification définissant une interaction entre un composant asynchrone avec backpressure. Par exemple, un répertoire de données, qu’on appellera un Publisher, produit des données qu’un serveur HTTP, un Subscriber, peut consommer à son rythme.
La programmation réactive avec Spring
Depuis sa version 5 (et Spring Boot 2), Spring propose WebFlux comme solution web réactive. Au contraire de son penchant web bloquant, Spring MVC, basé sur la Servlet API, WebFlux tourne sur des serveurs asynchrones et non-bloquants tels que Netty et Undertow, supportant les Reactive Streams et le backpressure. Le but de WebFlux est de proposer un moyen de prendre en charge un grand nombre de requêtes simultanément avec un nombre réduit de threads et de ressources. L’objectif étant d’avoir une application scalable (évolutive en français) et résiliente face aux fortes charges.
Reactive stream est une spécification dont la base est simple à comprendre, mais dont les spécificités et détails deviennent rapidement compliqués pour le commun des mortels.

Heureusement, nous n’avons nul besoin d’être Zach Galifianakis, car plusieurs solutions open-source sont apparues. Spring a pour sa part adopté le projet Reactor comme principale librairie réactive. Reactor fournit 2 types de Publisher afin de travailler avec des séquences de données : Mono, pour une séquence de 0 ou 1 élément, et le Flux pour une séquence de 0 à N éléments. En plus de ces types, Reactor fournit un riche ensemble d’opérateurs permettant de transformer le flux de données. Pour plus de détails sur Reactor, notamment la souscription aux Publishers, les flux chauds et froids (hot versus cold stream) ou la gestion des threads, voir la documentation officielle de Reactor.
Spring MVC vs WebFlux
Pour tester cela, nous allons fortement solliciter une application web Spring Boot réactive et une application Spring MVC, avec l’aide de Gatling. Les applications testées sont on-ne-peut-plus classiques : elles contiennent une API dont le but principal est de concaténer les chaînes « toto » et « toto » (oui je manquais d’imagination). Une concaténation de deux chaînes de caractères sur la JVM est plutôt triviale et rapide, et c’est pour cela qu’un délai fluctuant imitant l’accès à une ressource est appliqué. Pour cela, l’API sera séparée en trois endpoints qui :
- Concatène deux chaînes de caractères
- Idem, avec un délai pour la récupération d’un des deux chaînes de caractères
- Idem, avec des délais différents sur la récupération des deux chaînes de caractères
Le scénario Gatling appliqué fera appel aux trois endpoints simultanément avec un nombre X d’utilisateurs faisant Y requêtes chacun. Un « ramp-up » (une augmentation progressive du nombre d’utilisateur sur une période définie) sera préféré dans ces tests.
Conditions de test :
- Spring Boot 2.1.x
- Spring MVC avec Tomcat
- WebFlux avec Netty
- Java 11
- Hardware (voir à la fin de l’article)
1er test (pour se réchauffer un tantinet)
1000 utilisateurs, 4 requêtes chacun, et des délais fluctuants entre 0 et 200ms.
Rien de dramatique pour l’instant, résultats plutôt comparables, mais avec tout de même un petit avantage sur la moyenne des temps de réponse lors d’un double délai pour WebFlux (135ms pour Webflux vs ~210ms pour MVC). Ce résultat est plutôt attendu, car la programmation réactive est sensée rendre notre application plus robuste face aux demandes de ressource dont le temps de réponse est imprévisible. Nous tenterons d’exacerber un peu ce résultat.
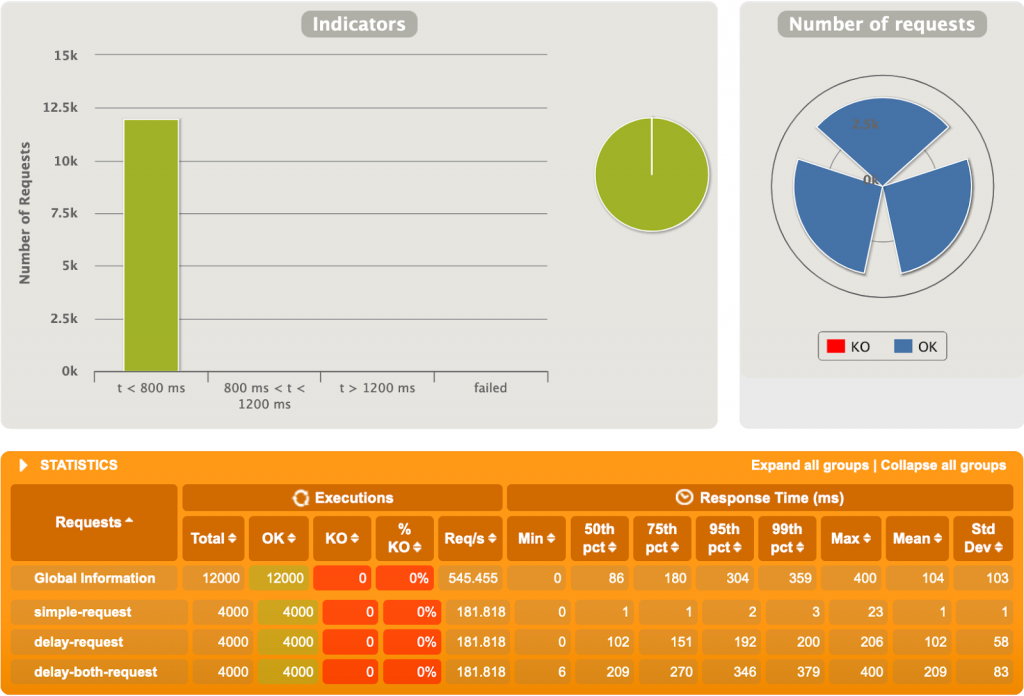
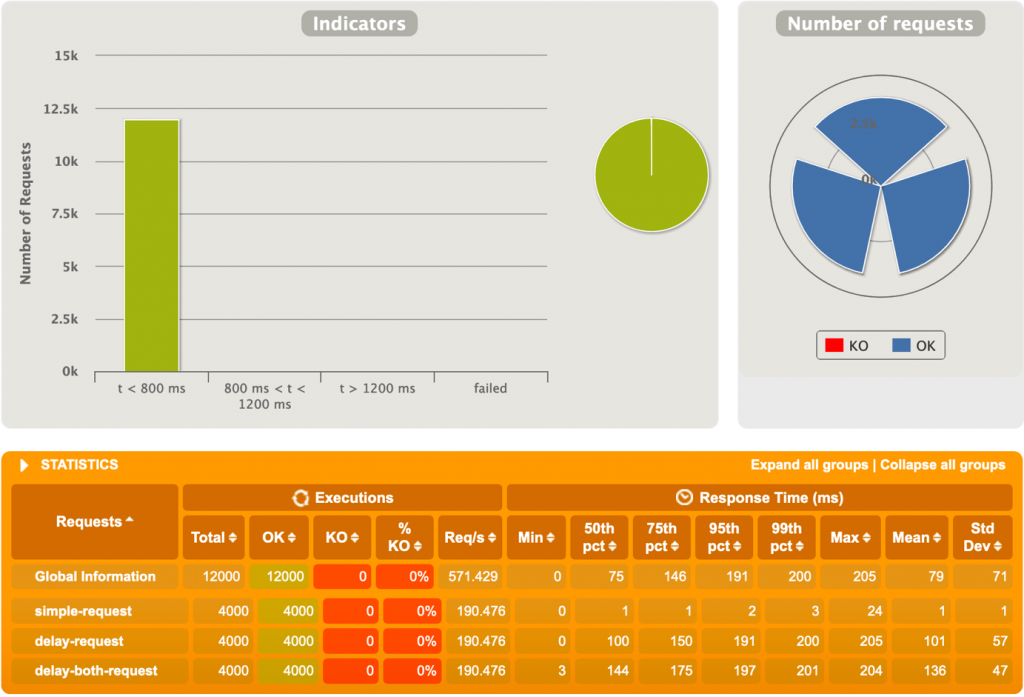
2ème test
1000 utilisateurs, 4 requêtes chacun, et des délais fluctuants entre 0 et 1000ms.
Nous entrons dans le vif de la comparaison. Rien qu’en regardant le temps de réponse moyen (~400ms pour WebFlux vs ~950ms pour MVC) nous voyons une différence notable. De plus, il est intéressant de voir que les temps de réponses pour la concaténation simple, qui est supposé n’avoir aucun délai explicite, ont explosé sur Spring MVC !
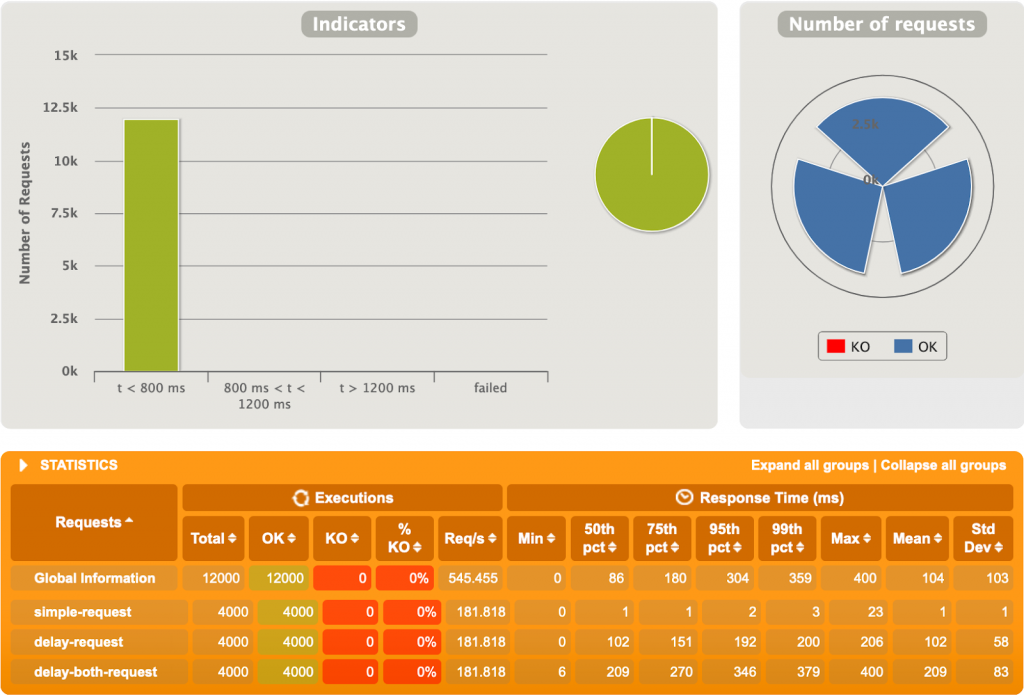
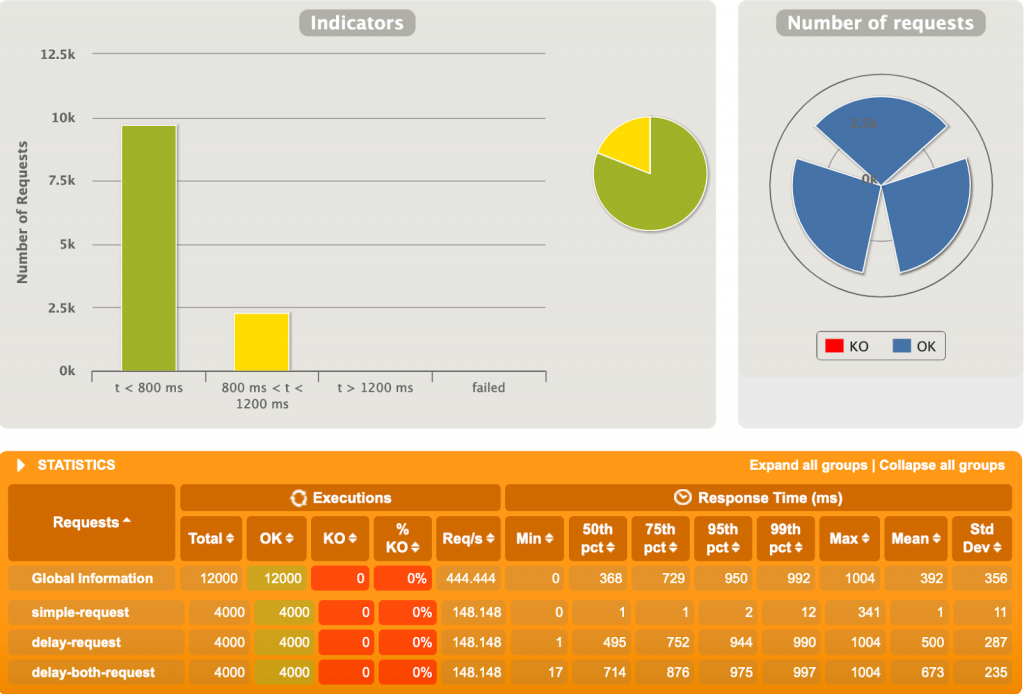
3ème test
10 000 utilisateurs, 4 requêtes chacun, et des délais fluctuants entre 0 et 1000ms.
Spring MVC s’est bien fait boxer ici. 10000 utilisateurs simultanément est probablement excessif, mais WebFlux s’en sort plutôt bien. Le temps de réponse moyen est ~45 fois plus faible sur WebFlux que sur MVC. C’est énorme. Un diagramme intéressant est le « Nombre de requêtes par seconde » (Figure 3.2 et 3.4), représentant la quantité de requêtes que Gatling performe par seconde. On voit au début sur MVC qu’une grande quantité de requêtes est faite, pour ensuite décroitre jusqu’à garder un nombre stable, mais très petit, de requêtes par seconde. A l’opposé, sur notre application réactive (Figure 3.4), Gatling envoie plus de 6000 requêtes/seconde constamment. Notre application MVC n’arrive pas à traiter autant de requêtes simultanément due à la nature bloquante de l’application et du serveur.
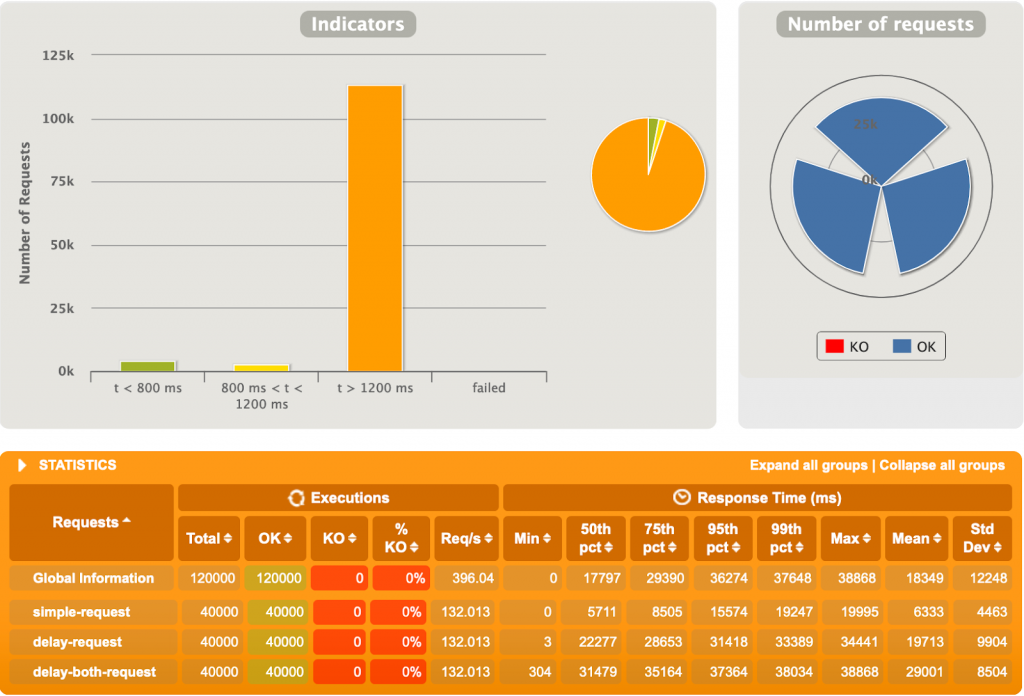
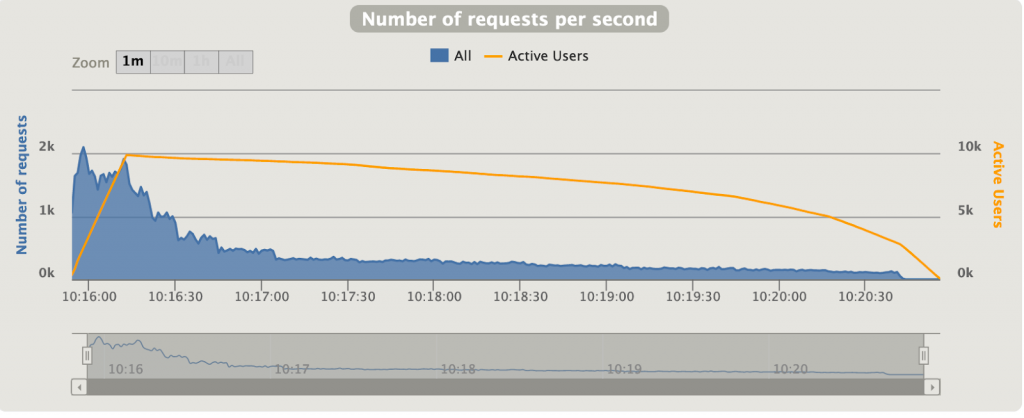
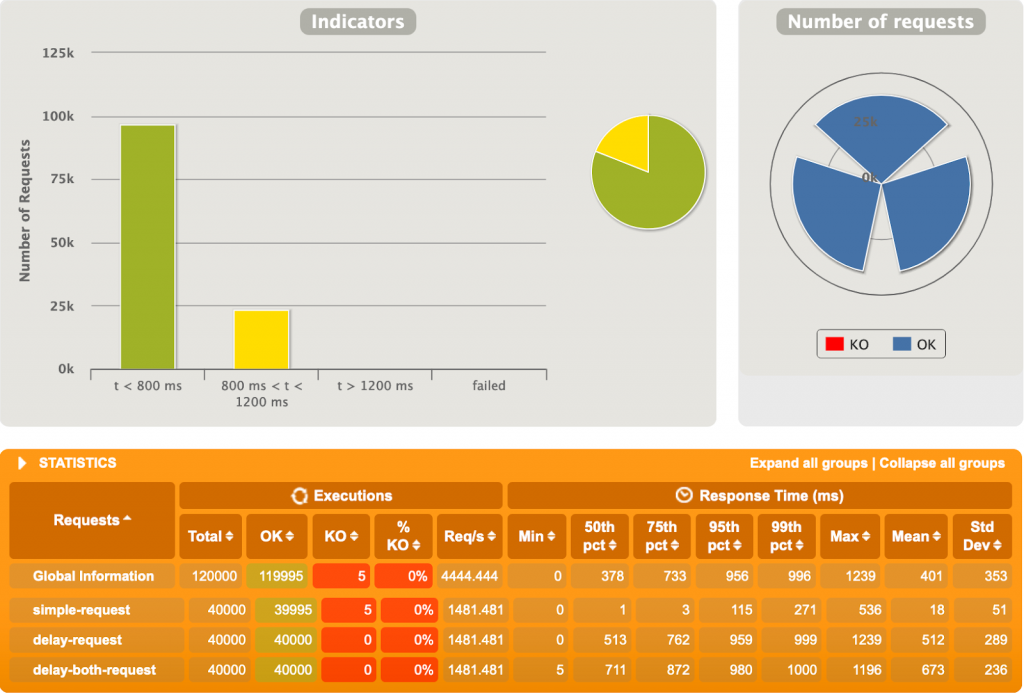
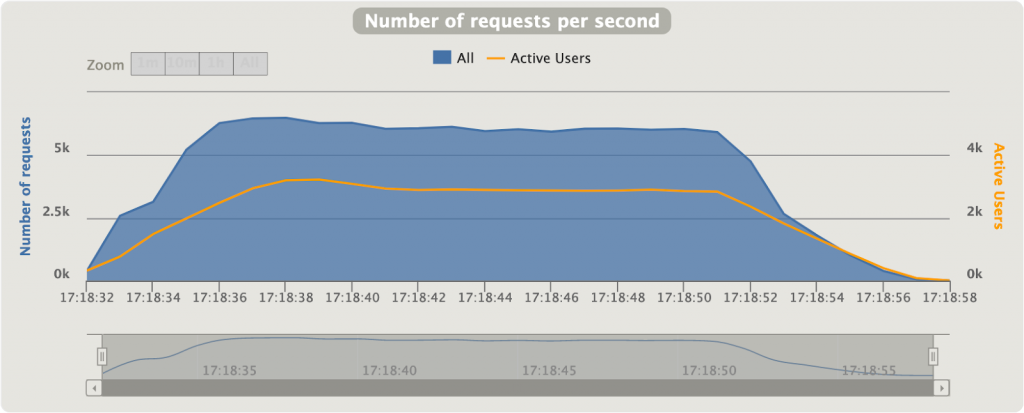
Alors que sur Spring MVC un Thread est alloué à une requête, thread qui reste bloqué sur la requête tant que celle-ci ne se termine pas, WebFlux parvient à administrer efficacement les requêtes imprévisibles afin qu’un thread ne reste pas bloqué indéfiniment. En effet, sur MVC nous aurons toujours un nombre maximum de threads existants, provenant d’un pool de threads. Sur une application MVC avec des temps de traitement variables et longuets, plusieurs requêtes peuvent facilement bloquer la réception de nouvelles requêtes en abusant des threads existants. WebFlux, lui, rend plus flexible l’allocation des threads, afin qu’un traitement bloquant ne bloque pas un thread qui pourrait être utilisé autrement en attendant la fin du traitement.
Aller plus loin
Après ces quelques jolis résultats mettant en avant la programmation réactive, il est important de se rappeler que WebFlux n’est pas la solution à tous les maux. Pour plus d’information sur les cas concrets d’utilisation, se référer au chapitre sur l’applicabilité dans la documentation officielle (voir les liens utile).
Pour aller plus loin dans les tests, il serait intéressant d’analyser d’autres comportements avec différents paramètres d’entrée, notamment sans un « Ramp-up » initial ou en modifiant les délais minimums et maximums. Finalement, des tests comparant la consommation mémoire des 2 types d’application seraient très intéressants.
Quid des bases de données ?
Une application réactive montre rapidement ses qualités lors de requêtes demandant un temps de traitement variable, par exemple les traitements I/O-intensive telles qu’une requête http ou en base de données. Ce genre de traitement étant particulièrement lourd, il est normal de se dire qu’une solution réactive aiderait grandement les performances d’une application, afin qu’un thread ne soit pas bloqué par une requête prenant trop de temps.
Nous allons nous pencher sur R2DBC, la solution réactive de Pivotal/Spring pour les bases de données relationnelles. R2DBC, l’acronyme de « Reactive Relational Database Connectivity », n’est toujours pas officiellement publiée et est donc sujette à changements, améliorations… et nombreux bugs.
Similairement aux tests précédents, nous allons comparer une application Spring MVC connectée à une base de données PostgreSQL à l’aide des Repository Spring Data et JDBC, avec une application réactive similaire mais utilisant R2DBC. Les tests Gatling utiliseront une API qui :
- Récupère un élément
- Récupère plusieurs éléments
- Créée un nouvel élément
Rien de compliqué donc, mais il sera intéressant de voir si R2DBC est comparable à JDBC sur une application aussi simple.
Conditions de test :
- Idem que les tests précédents
- Spring Data R2DBC 1.0.0.M1 et R2DBC PostgreSQL 1.0.0.M7
- Spring Data JDBC 2.1.x
- PostgreSQL 9.6
1er test
10 utilisateurs, 4 requêtes chacun.
La différence ne semble pas être trop dramatique pour l’instant. Il faut se rappeler que la force de la programmation réactive apparaît lors de fortes charges, il est donc logique de se dire que R2DBC montrera ses qualités à ce moment-là…
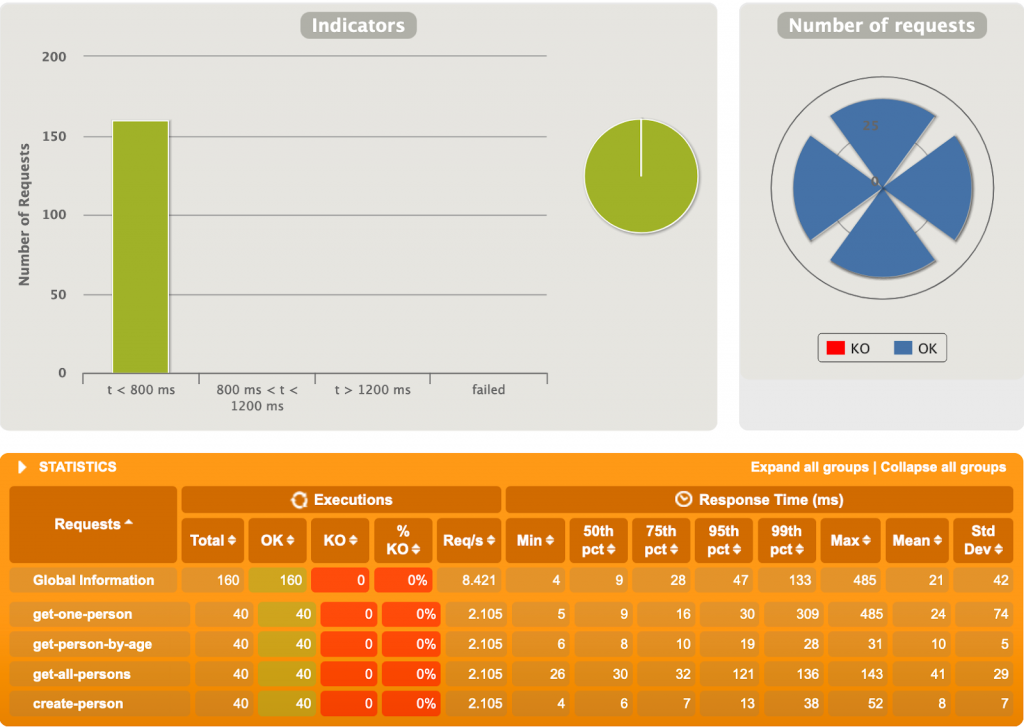
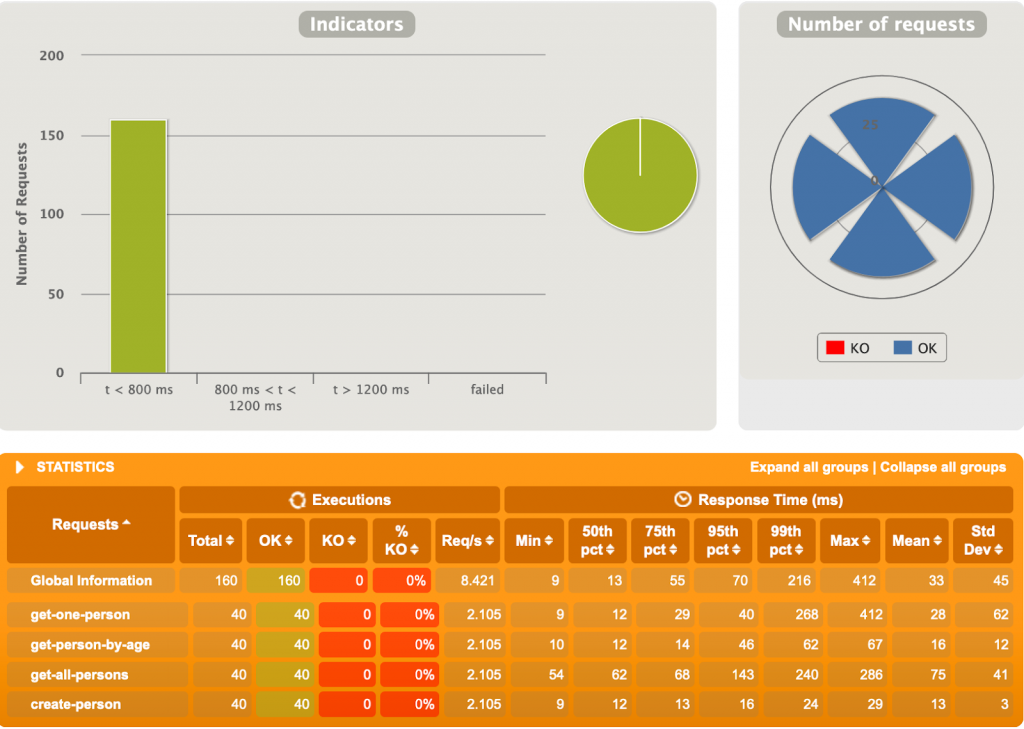
2ème test
100 utilisateurs, 4 requêtes chacun.
Petite déception. R2DBC peine rapidement ici, alors que JDBC a un temps de réponse moyen bien moindre.
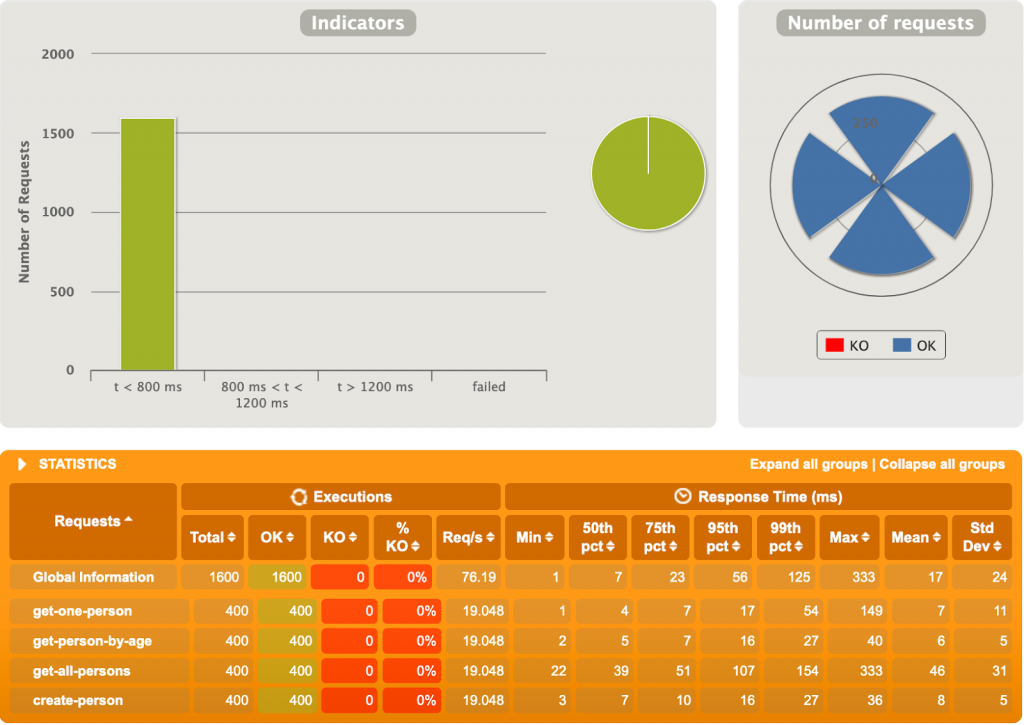
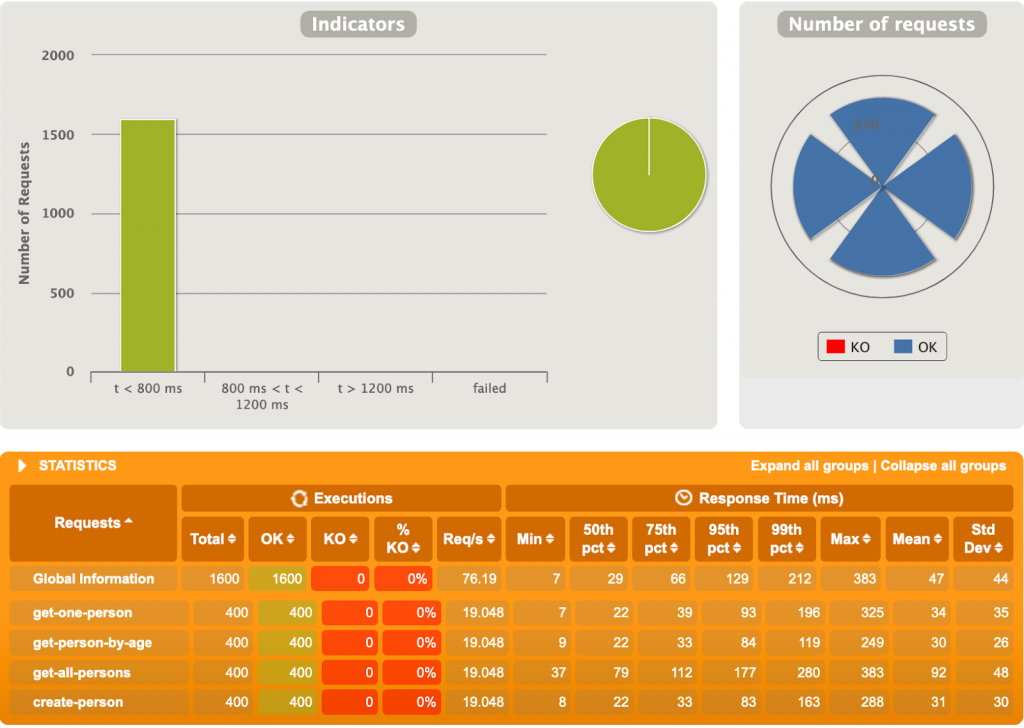
3ème test
500 utilisateurs, 4 requêtes chacun.
Et là, c’est le drame. Près d’un quart des requêtes tombent en erreur, avec celles en succès tout de même beaucoup plus lentes comparées à l’application Spring MVC. L’erreur, certes très polie, provient directement de PostgreSQL :
“org.postgresql.util.PSQLException: FATAL: sorry, too many clients already“
Cela veut dire que l’application tente d’ouvrir plus de connections que permises par la configuration (100 lors de ces tests). Il semble qu’en ce moment R2DBC ouvre plus de connections que nécessaires en ne prenant pas en compte la quantité maximale de connections permises. Il est probable que ce soucis sera réglé dans le futur.
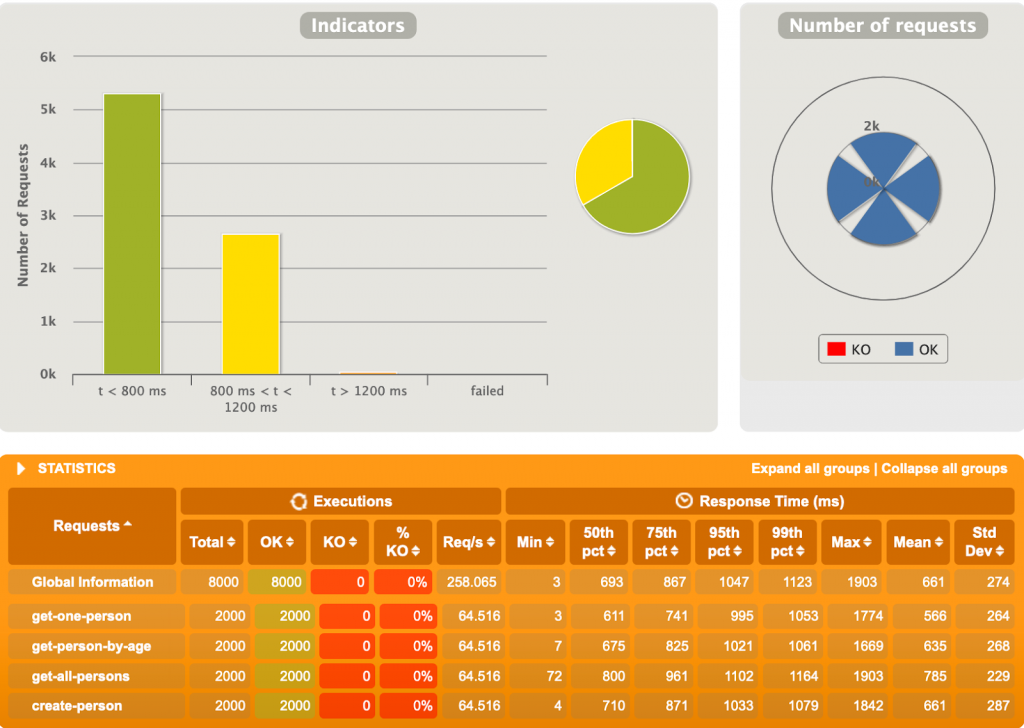
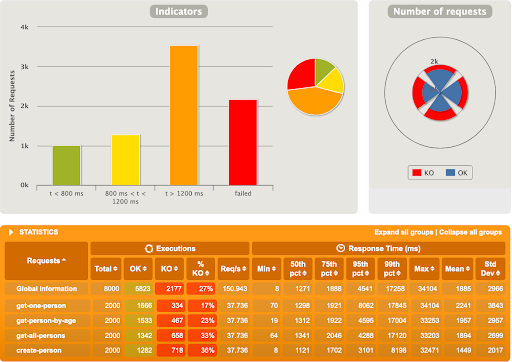
Après ces tests assez basiques, nous pouvons voir que JDBC a encore quelques avantages face à la concurrence R2DBC et de belles années devant lui. Il faut se rappeler que R2DBC est toujours en cours de développement, et pourrait même être vu comme un projet d’incubation sur les drivers relationnels non-bloquants. R2DBC (en tout cas pour le driver PostgreSQL) n’est donc pour l’instant pas prêt pour la production. Mine de rien, les possibilités offertes par R2DBC restent tout de même intéressantes, et son futur ne peut qu’être meilleur. Rendez-vous automne 2019 pour la première Release Candidate !
Aller plus loin
Le projet R2DBC étant jeune et pas encore intégré à Spring Boot, peu de configurations sont pour l’instant possibles afin de tester avec différentes propriétés. Aussi, au fur et à mesure que le projet se développe, de nouveaux tests exécutés sur des versions plus récentes aideraient à voir où le projet est rendu. Enfin, tester avec les autres drivers disponibles sur R2DBC (H2 et Microsoft SQL Server) permettrait de voir si un driver particulier sort du lot.
Liens utiles
- Repo Git du projet : https://github.com/ekino/spring-reactive-perf
- Spring Data R2DBC : https://docs.spring.io/spring-data/r2dbc/docs/1.0.x/reference/html
- Repository Git de R2DBC : https://github.com/r2dbc
- Reactor : https://projectreactor.io/docs/core/release/reference
- Choisir entre WebFlux et MVC : https://docs.spring.io/spring/docs/current/spring-framework-reference/web-reactive.html#webflux-framework-choice
- La spécification des Reactive Streams sur la JVM : https://github.com/reactive-streams/reactive-streams-jvm
Hardware
- MacBook Pro (Retina, 15-inch, Mid 2015)
- Processeur 2,2 GHz Intel Core i7
- Mémoire 16 GB 1600 MHz DDR3
Remerciements
Un grand merci à Yann Le Guern pour ses tests initiaux sur R2DBC, ainsi qu’à @philippe_agra, @clemstoquart et Nicolas Gunther pour leur précieuse aide.