Vincent Laurier, Développeur PHP chez ekino revient sur le Forum PHP 2018
Ce que Vincent Laurier retient du Forum PHP 2018

Symfony/Messenger, un composant à votre service. (Stéphane Hulard)
La première conférence à laquelle j’ai assisté, exposait un nouveau composant Symfony : Messenger. Stéphane Hulard (@s_hulard), l’orateur, a commencé par rappeler l’état actuel des choses : Messenger est toujours en version expérimentale pour SF4.1, et une version stable est éventuellement prévue pour la 4.3.
La présentation, claire et accessible, avait pour but d’exposer les concepts clés. Le composant sert à communiquer de façon globale avec des systèmes extérieurs, et il propose une abstraction par le biais d’interfaces. Bien qu’orienté pour un usage asynchrone, il est possible de l’utiliser pour des traitements synchrones, car la bascule s’effectue au niveau de la configuration. On peut ainsi bénéficier en amont des concepts. Ils apportent une architecture déjà prête pour l’asynchrone.
Le « Message » est un objet central de l’implémentation, à l’instar de l’objet « Event » dans l’EventDispatcher de Symfony. Mais il existe une différence notoire : la diffusion d’un message est unidirectionnel, c’est-à-dire, qu’aucune réponse n’est attendue. Rappelons qu’un événement quant à lui peut-être transféré et altéré au cours de sa propagation.
Un message ne devrait comporter que ce qui est vraiment nécessaire à son traitement. Il ressemble à un DTO (Data Transfert Object) qui peut être sérialisé.
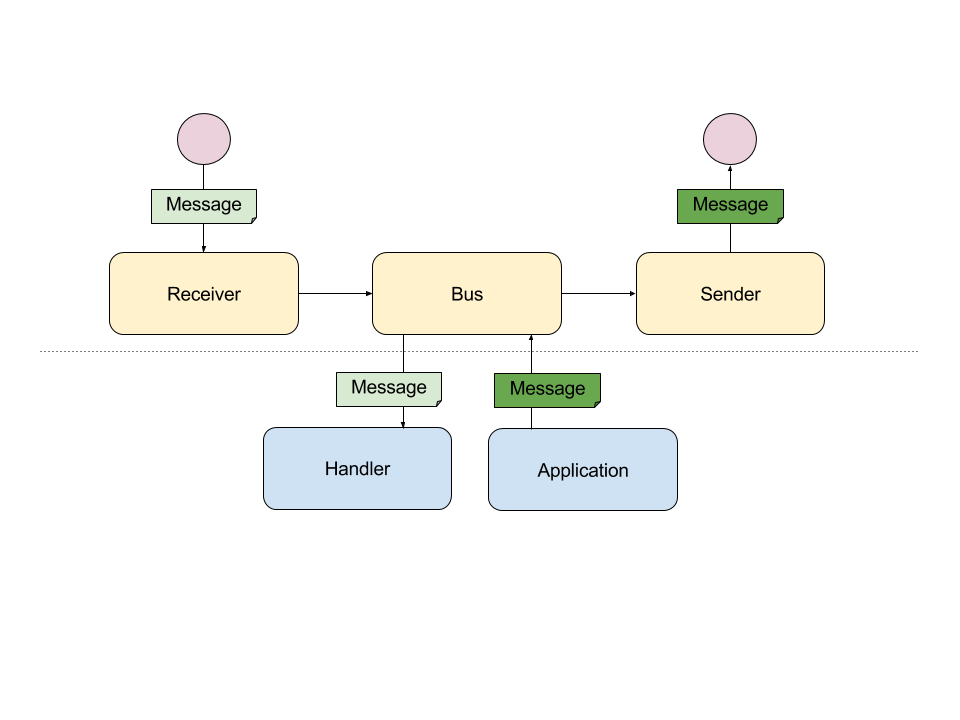
L’architecture du composant quant à elle se présente de la façon suivante :
https://symfony.com/doc/current/components/messenger.html
La ligne pointillée horizontale sépare la partie qui communique avec l’extérieur de celle représentant la logique métier de notre application. Le Receiver et le Sender se chargent plus précisément de la réception et de l’envoi du message avec des systèmes tiers. Quant au Bus, il véhicule ce même message vers un Handler approprié de l’application. Chose importante : un message a pour vocation à être traité, sans quoi une erreur survient, contrairement à un Event par exemple, pour poursuivre la comparaison.
Autre mot clé essentiel: le Middleware, qui permet d’ajouter de la logique métier autour d’un message, comme par exemple pour le valider ou pour l’enrichir.
Par ailleurs, dans son exemple, Stéphane Hulard a montré comment exécuter un message via une commande Symfony. Je vous invite donc à jeter un œil à l’implémentation dans les slides, que vous pourrez compléter par la documentation officielle :
Pour finir, j’ajouterais que Messenger supporte déjà de nombreux protocoles par le biais d’adaptateurs, parmi lesquels AMQP, ZeroMQ, SQS… Il serait probablement intéressant de comparer le composant à d’autres solutions telles que Sonata Notification par exemple.
Les slides : Symfony/Messenger un composant à votre service
La cuillère n’existe pas. (Timothée Barray)
Timothée Barray (@timbarray) nous a raconté comment le passage d’un entretien l’a motivé à réaliser cette présentation alors qu’il avait posé la question : « Où en êtes-vous par rapport aux tests ? »
Il nous a alors plongé dans une situation fictive, comparant le travail de deux développeurs.
Tandis que le premier, doté de bonnes facultés d’abstraction se lançait systématiquement dans une implémentation des fonctionnalités, le second avait besoin d’exemples concrets.
Il en résultait deux systèmes d’itérations différents :
Implémentation, suivi d’une vérification manuelle du bon fonctionnement dans le premier cas. Écriture des tests, suivi d’une implémentation dans le second.
Il s’est alors livré à un calcul purement comptable d’estimation des coûts par rapport au temps passé. Sa conclusion était un surcoût lié à l’écriture des tests.
C’était le point de départ de son argumentation : que gagne-t-on à investir sur ce plan ?
Au-delà du but premier d’un jeu de tests qui est de valider des comportements en minimisant les régressions, je pense qu’il a surtout voulu mettre l’accent sur le bénéfice d’un point de vue humain.
Tester, c’est notamment s’offrir une documentation à jour avec le code. Cela facilite grandement l’entrée de nouveaux développeurs sur le projet. Tester, c’est pouvoir focaliser son temps futur sur des tâches utiles au développement de l’application, plutôt que d’effectuer, aussi bien pour le développeur que pour le chef de projet, une recette qu’il faudra refaire chaque fois. Du processus de tester découle aussi nombre de bénéfices : se poser des questions en amont, mettre en lumière la compréhension, déceler les incohérences le plus tôt possible, améliorer l’architecture du code, se rapprocher du besoin et du langage métier…
Cette conférence est assurément à conseiller aux sceptiques s’il en reste encore, qu’ils soient techniques ou non.
Les slides : La cuillère n’existe pas
Générateurs et Programmation asynchrone. (Benoît Vigier)
Bien que toutes les conférences de cette deuxième journée du forum PHP aient été d’un excellent niveau, celle-ci a eu ma préférence. Tout y était, autant la forme que le fond : la vulgarisation du concept d’événements asynchrones, l’explication en profondeur des générateurs, suivi d’un cas concret d’utilisation, à ma connaissance très peu répandu. Je vous recommande vivement de visualiser cette présentation.
Benoît Vigier s’est appuyé sur une analogie avec une situation de la vie réelle : vous êtes en train de prendre un thé en terrasse avec quelqu’un. Aussi, lors de ce rendez-vous, vous exécutez au final trois tâches en parallèle : boire, discuter et respirer. Ces trois tâches peuvent être découpées en plusieurs opérations qu’il a qualifié d’interne ou d’externe. Par exemple, discuter c’est parler et écouter. Parler est externe selon sa définition car l’opération empêche d’autres actions, comme celle de boire par exemple. Écouter par contre est interne, car elle permet d’avancer sur d’autres opérations. Il a donc schématiser la situation comme une boucle d’opérations (un « tick ») qui fait progresser chacune des trois tâches principales.
Le lien avec les générateurs a ensuite été établi en montrant comment ceux-ci communiquent avec l’extérieur. Le mot clé yield est porteur d’un double sens: il signifie aussi bien «produire » que « récolter », et permet un jeu de bascule entre le générateur et le code qui l’appelle. Cette communication s’effectue également par l’usage des méthodes de l’interface Iterator qu’un générateur implémente, en plus d’en proposer trois autres: send, getReturn et throw.
Il est alors possible de bénéficier de la puissance des générateurs pour introduire des traitements asynchrone s: on « yield « des promesses. C’est l’idée majeure des librairies qui facilite l’usage de l’asynchrone en PHP : reactphp/react, amphi/amp M6Web/tornado.
L’orateur a également discuté des promesses plus en détail : ces fonctions dont on n’attend pas une réponse immédiate, mais pour lesquelles il est possible de déclencher un traitement ultérieur via une fonction de rappel. Il a alors mentionné le manque de lisibilité à juste titre des promesses de type « Thenable » dès lors qu’elles sont chaînées et que l’on souhaite gérer tous les cas de retours, succès, réussite.
Je ne détaillerai pas davantage le contenu riche de cette présentation, mais j’espère pour ma part avoir l’occasion de creuser le sujet que je trouve très prometteur.
Les slides : Générateurs et programmation asynchrone
Quelle différence y-a-t-il entre le bon et le mauvais repository ? (Arnaud Langlade)
Seul petit couac d’organisation de cette édition 2018, par ailleurs superbement orchestrée : le choix de la salle pour cette conférence, victime de son succès.
C’est debout, au fond de la salle « Grace Hopper », plus petite que sa voisine, la salle « Katherine Johnson » que j’ai malgré tout pu écouter Arnaud Langlade (@arnolanglade).
À l’image du titre évocateur, la présentation avait pour fil rouge le sketch des inconnus. Mais je vous rassure de suite, les explications étaient bien plus limpides !
N’ayant pu prendre de notes, j’évoquerai simplement les idées qui m’ont paru majeures dans la présentation.
En premier lieu : ce qu’il faut éviter dans un repository.
Il ne faut pas en faire un entrepôt de requêtes au jeu de données, en y entassant les méthodes avec des noms divers et variés, et des types de retours différents : tantôt un tableau, tantôt une chaîne de caractères, tantôt une entité, tantôt un QueryBuilder, etc…
Il ne faut pas non plus coupler directement son code à l’infrastructure (comprendre ici, au framework !)
Comment donc s‘orienter vers la bonne voie ?
Tout d’abord en définissant une abstraction claire, par le biais d’une interface par exemple. Le Repository concret qui l’implémentera, garantira que l’on ne manipule que des données bien structurées. Dans son exemple, le Repository de Galinettes, se borne à la manipulation d’entités de type Galinette, aussi bien en lecture qu’en écriture.
Aussi, l’orateur a mis l’accent sur une précaution à prendre : n’implémenter que des méthodes qui font sens au niveau métier. Pour illustrer ses propos, la fonction Remove n’existait pas dans le Repository, car du point de vue métier, la fin de vie de l’animal ne s’opérait que par un lâché de Galinettes.
Enfin, la définition d’une interface permet de tirer un bénéfice immédiat. Le véritable Repository peut embarquer en dépendance une connection par exemple. Cela autorise l’exécution de requêtes natives, et permet de tirer profit des spécificités du moteur de base de données utilisé.
Les slides : Quelle différence y a t-il entre le bon et le mauvais repository ?
Comprendre le fonctionnement de l’analyse statique (Damien Seguy)
En début d’après-midi, Damien Seguy (@faguo) nous a fait découvrir le fonctionnement de l’analyse statique. Il en a d’abord rappelé le but : permettre de faire de la revue de code automatisée.
Le principe repose sur l’AST : Arbre de syntaxe abstraite. C’est une représentation du langage qui expose la façon dont les informations et les opérateurs sont organisés.
La première étape s’appelle la « tokenisation ». Elle convertit le fichier PHP, qui n’est rien d’autre qu’un fichier texte au final, pour obtenir cette représentation sous forme d’arbre. Les délimiteurs tels que les parenthèses ou les accolades sont retirés, car ce ne sont rien d’autre que des conventions de codage.
Après cette introduction, l’orateur a cherché à nous faire percevoir toute la difficulté des problématiques sous-jacentes. Comment par exemple reconnaître une fonction morte dans le code ?
Sous sa forme la plus immédiate, c’est une fonction dans l’arbre qui n’est reliée à aucune autre. Mais est-ce le seul cas de figure ? Non. Une fonction morte appelée par une autre fonction morte doit également être détectée… Pire encore, une fonction morte qui s’appelle récursivement, ou bien encore de la récursivité sur plusieurs niveaux entre diverses fonctions mortes…
Damien Seguy a su, par de multiples questions de ce genre, mettre en exergue la complexité de l’analyse statique de code. Par ailleurs il a su nous étonner en nous présentant un graphique issu de l’analyse statique. Celui-ci révélait que certains développeurs vont jusqu’à définir des fonction avec 57 paramètres ! Amusant.
Cessons les estimations ! (Frédéric Leguédois)
Une prestation qui se regarde plus qu’elle ne se raconte ! Prestation, le terme est pesé, car c’est un vrai One Man show plein d’humour que nous a offert Frédéric Leguédois (@f_leguedois).
Il a su habilement tourner en ridicule toutes les méthodes employées pour réaliser des estimations, avec une idée maîtresse – qu’il s’agisse au final d’une perte de temps – car celles-ci ne sont jamais fiables. Si je devais retenir une phrase de cette conférence, ce serait celle-ci :
« Les estimations, c’est la différence entre le rêve et la réalité ».
Boostez vos applications avec HTTP/2 (Kévin Dunglas)
Lors de cette présentation, Kévin Dunglas (@dunglas) nous a invité à utiliser dès à présent HTTP2.
Il a d’abord fait un rappel historique sur HTTP en version 1. Je ne m’étendrai pas sur l’ajout progressif des fonctionnalités. Vous pourrez les retrouver sur les slides par vous même au besoin. La remarque importante, c’est qu’encore aujourd’hui, la version 1 d’HTTP couramment utilisée est proche de celle de 1997 ! Et elle comporte une restriction majeure : lors de l’interrogation du serveur par le client, une connexion TCP est ouverte, puis coupée dès que le client a reçu sa réponse. Ainsi typiquement pour l’interrogation d’une page web, il faut une connexion pour récupérer la page web, puis autant que nécessaire pour appeler les ressources associées : css, js…
Grâce à HTTP2, issu du projet SPDY de Google, il est maintenant possible grâce à la notion de Multiplexing d’effectuer plusieurs requêtes au sein d’une même connexion TCP. L’ordre de celles-ci reste par ailleurs respecté. Autre évolution majeure : le protocole échange de la donnée binaire, plus optimisée que le format textuel préalable. HTTP2 est ainsi 2,29 plus rapide qu’HTTP, mais nécessite du HTTPS pour fonctionner. Il est déjà supporté par 86 % des utilisateurs (https://caniuse.com/#feat=http2). Pour le développeur par contre, une extension navigateur sera nécessaire pour lire les entêtes par exemple. Sur Chrome, l’outil est déjà présent.
Une autre force d’HTTP2 est de permettre au serveur d’envoyer de la donnée vers le client avant que celui-ci ne la demande. On peut ainsi améliorer l’expérience utilisateur et gagner en rapidité par du préchargement. Ceci s’effectue par l’ajout d’une entête http : « W3C preload ».
Dans Symfony, le support d’HTTP2 est assuré via le composant WebLink, qui implémente la PSR-13.
Enfin, concernant le push de données, Kévin Dunglas a présenté un nouveau protocole : Mercure.
Il fonctionne grâce à un Hub. C’est un serveur externe qui diffuse les mises à jour aux différents clients ayant appelé l’application avec les bonnes entêtes. Le push de données déclenche alors un événement JavaScript chez le client qui permet de mettre à jour l’information. Pour clôture sa présentation, l’orateur a annoncé l’intégration de Mercure avec Symfony et API Platform.
Les slides : Boostez vos applications avec HTTP/2
Développeurs de jeux vidéos (les rois de la combine: Laurent Victorino)
Dernière présentation de ce forum. Rien à voir avec PHP, mais relativement récréative.
Laurent Victorino (@on_code) a dévoilé les secrets de certains bugs dans des jeux vidéos.
Pour l’anecdote, la combine qui m’a le plus amusé concernait un jeu d’aventure 3D, Jak and Daxter, dans lequel le personnage trébuche parfois de façon aléatoire. Les joueurs pensaient à un objet caché ou autre. De nombreuses hypothèses étaient émises alors qu’il n’en était rien. De fait, la carte du jeu, parfois constituée de nombreux polygones, mettait simplement trop de temps à charger. Les concepteurs ont décidé pour en gagner, de faire tomber le personnage quand cela se produisait !
Des présentations techniquement intéressantes et parfaitement préparées par les orateurs, une organisation très bien rodée, j’ai trouvé très stimulante cette édition 2018 du forum PHP. Elle a montré une fois encore la richesse de l’univers autour de PHP, aussi bien par la diversité des sujets abordés que par le dynamisme de sa communauté.
Rendez-vous l’année prochaine !