Améliorer le suivi d'exploitation avec Logstash & Kibana
L'exploitation 24/7 de plateformes de production Web est un défi de tous les jours (et nuits !) pour garantir à nos clients et services internes une qualité de service maximale.

En résumé l’exploitation en phase de “run” (on appelle “run” la phase de vie d’une plateforme ou application, par opposition au “build” ou mise en place) consiste en 2 volets :
le curatif : résoudre les incidents lorsqu’ils se produisent (redémarrer un Tomcat, identifier une ressource en sur-consommation de CPU, isoler un nœud défaillant, …)
le préventif : mettre en place des outils, indicateurs et processus pour anticiper les incidents et mettre en place un plan d’action pour les mitiger (suivre la volumétrie d’un système de fichier et prévoir lorsqu’il sera plein, déplacer une application consommatrice d’I/O disque sur un nœud plus performant, …)
Ce second volet est essentiel : anticiper vaut toujours mieux que de travailler dans l’urgence (surtout lorsque cette dernière se produit à 3 heures du matin).
Chez Ekino nous monitorons environ 500 équipements (serveurs physiques, machines virtuelles, switchs, routeurs,…) et 5500 services pour nos clients. Tous les lundis, l’ensemble de l’équipe infrastructure se réunit pour débriefer de la semaine d’exploitation écoulée et lister les événements à venir (mise en production sur une plateforme, campagne de communication critique pour un client, …).
Chaque fois qu’il est intervenu durant la semaine, l’ingénieur d’astreinte enrichit un évènement dans un outil de suivi de façon à enregistrer la plateforme, le service, les constats et les actions effectuées. Ce journal est donc une première source d’informations sur les incidents récurrents, mais il est clairement insuffisant :
- Il apporte peu d’éléments quantifiables et ne donne qu’une vue court terme.
Il ne remonte que les incidents “durs” (qui ont nécessité une intervention) mais ne met en évidence ni les problèmes émergents (load proche du seuil d’alerte, …) qui risquent de devenir des problèmes dans le futur, ni les incidents qui ont été traités automatiquement (par des outils type Monit).
Il faut donc s’outiller pour compléter le feedback “humain”.
La stack “ELK”
Pour le cas décrit dans cet article nous avons choisi de mettre en place la suite “ELK” (ElasticSearch / Logstash / Kibana) d’ElasticSearch BV :
- La communauté est très active.
- Nous l’avons déjà mise en place sur d’autres projets.
- Sa mise en place est simple.
- Elle permet d’exploiter une donnée déjà existante : les logs.
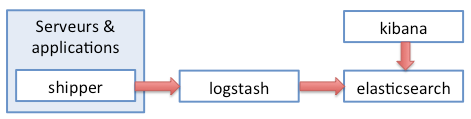
L’architecture de la stack est assez simple :
- des shippers s’occupent de récupérer les log ;
- un ou plusieurs nœuds Logstash découpent les log en éléments sémantiques (un timestamp, un serveur, une action, un résultat, un code de retour, …) et le transmettent à Elasticsearch ;
- un ou plusieurs nœuds Elasticsearch indexent et stockent ;
- Kibana gère la présentation en se basant sur les données lues dans Elasticsearch
L’envoi (shipping) des logs
Initialement utilisateurs du vénérable Nagios, nous avons basculé vers son fork Icinga début 2013. Les deux outils sont très similaires et ont la bonne idée de partager leur format de log.
Notre architecture de supervision est basée sur plusieurs nœuds Icinga (permettant entre autres de tester nos services depuis l’extérieur de notre infrastructure).
L’envoi des logs est ici effectué par logstash-forwarder (anciennement Lumberjack). Il a l’avantage d’être extrêmement léger en ressources et d’envoyer les logs cryptés via TCP. Sa configuration est très simple :
{
"network": {
"servers": [ "votreserveurlogstash:port" ],
"ssl certificate": "votrecertificat.crt",
"ssl key": "votrecertificat.key",
"ssl ca": "votrecertificat.crt",
"timeout": 15
},
"files": [
{
"paths": [ "/var/log/icinga/icinga.log" ],
"fields": { "type": "nagios" }
}
]
}
Logstash, patterns et groks
Logstash reçoit donc ligne par ligne nos logs. Grâce au type:nagios enrichi par logstash-forwarder il va pouvoir déterminer à quel type de log il a affaire et quel traitement il doit lui appliquer. La configuration comporte 3 sections :
- input qui permet de définir un ou plusieurs modes d’entrée (TCP, Redis, …)
- filter qui permet de définir les traitements à appliquer à chaque type de log
- output qui définit les sorties (Elasticsearch, Graphite, Jira, RabbitMQ, …)
input {
lumberjack {
port => 3333
ssl_certificate => "votrecertificat.crt"
ssl_key => "votrecertificat.key"
}
}
filter {
if [type] == "nagios" {
grok {
match => { "message" => "%{NAGIOSLOGLINE}" }
}
date {
match => [ "nagios_epoch", "UNIX" ]
}
date {
match => [ "nagios_epoch", "UNIX" ]
target => "hour"
}
mutate
{
convert => [ "hour", "string" ]
gsub => [
"hour", "dddd-dd-dd ", "",
"hour", " ...", "",
"hour", ":dd:dd", ""
]
}
}
}
output {
elasticsearch {
embedded => false
host => "hostElasticsearch"
cluster => "clusterElasticsearch"
}
}
La ligne “match => { “message” => “%{NAGIOSLOGLINE}” }” permet d’indiquer le pattern sémantique à appliquer. Nagios étant très répandu, Logstash propose en standard un pattern applicable.
Nous appliquons ensuite un premier traitement pour réécrire le timestamp du log. En effet, par défaut, Logstash considère qu’il reçoit les logs en direct et horodate la ligne lors de la réception, ignorant le timestamp de la ligne de log elle même. Le délai de traitement ou tout simplement un travail asynchrone rendent cette pratique dangereuse. Nous allons donc appliquer un filtre date pour dire à Logstash d’utiliser le timestamp contenu dans la ligne de log.
Nous souhaitons par ailleurs obtenir des statistiques sur les heures de déclenchement des événements Icinga. Nous allons donc extraire cette donnée et la stocker dans un champ séparé.
La configuration Elasticsearch est, quant à elle, tout à fait standard, cet article ne reviendra donc pas dessus.
Conseil : lors de la mise en place initiale rajoutez temporairement dans la configuration Logstash un input de type :
tcp
{
port => 3334
type => "nagios"
}
Vous pourrez ainsi injecter l’historique de vos logs via un :
nc votreserveurlogstash 3334 < loghistorique
Kibana et le tableau de bord Icinga
Kibana s’installe très simplement avec un Apache ou un Nginx.
Le point essentiel à retenir est que le rendu est fait côté navigateur. L’utilisateur a donc besoin de pouvoir requêter Elasticsearch. L’ouverture de flux directe vers Elasticsearch étant déconseillée pour des questions de sécurité (voir scripting and security), il est donc préférable de “reverse-proxyfier” les flux pour tout faire passer par l’Apache / Nginx. Une configuration d’exemple est disponible sur le github Elasticsearch.
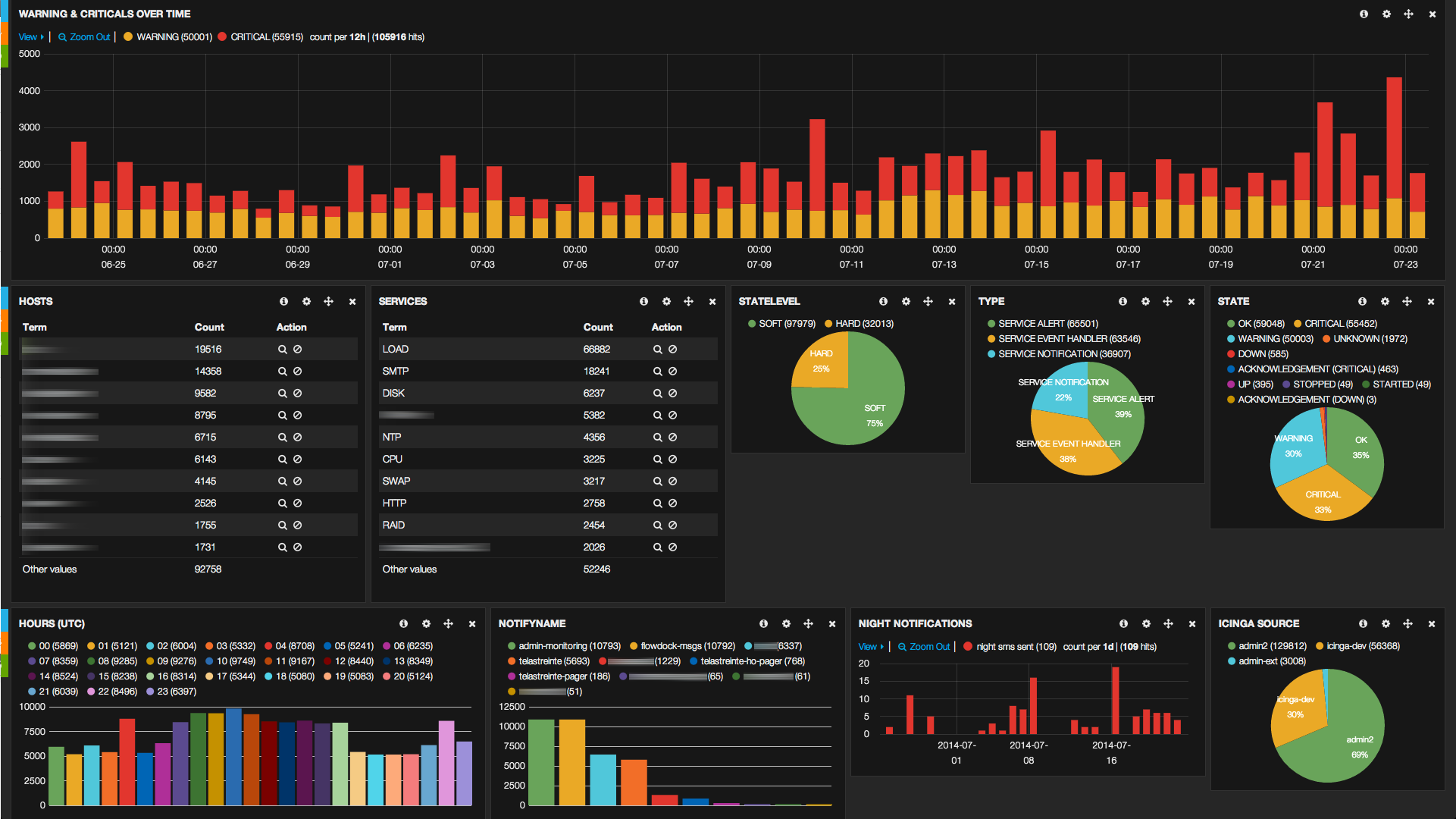
Nous voici donc avec des logs agrégés depuis nos instances Icinga. Il s’agit maintenant d’en tirer des informations via un tableau de bord que nous avons construit :
Analyse
Ce tableau de bord type présente plusieurs informations :
- la volumétrie de warnings et criticals remontés par Icinga dans le temps
puis des informations permettant d’orienter le diagnostic et de déterminer les pistes d’action prioritaires :
- le top 10 des serveurs (hosts) problématiques,
- le top 10 des services problématiques (qu’ils soient infra ou applicatifs),
- la répartition des alertes soft / hard,
- la répartition des types de notifications.
Enfin des statistiques sur les déclenchements qui permettront d’évaluer l’impact humain de l’exploitation
- heures de déclenchements
- noms des personnes (ou des bots) notifiés
- nombre d’alertes SMS par nuit
L’incident était-il isolé ?
Filtrer sur le host et le service en question, zoomer en arrière de façon à englober plusieurs semaines : l’éventuel pattern de répétition est immédiatement visible.
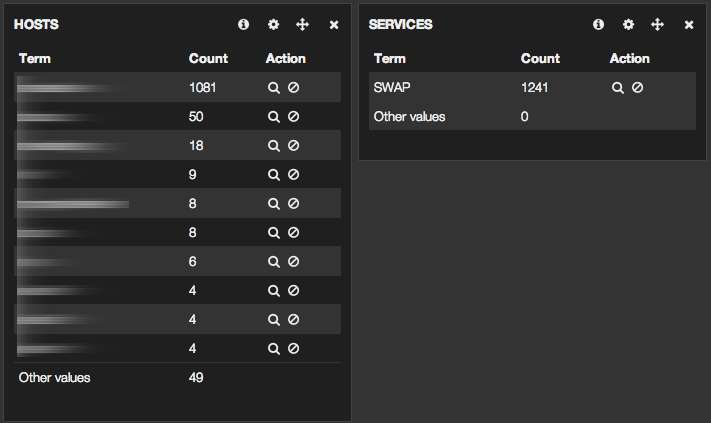
Quelles machines swapent ?
Filtrer sur le service “swap”. Le top 10 des hosts indique les serveurs à cibler pour un ajustement de mémoire.
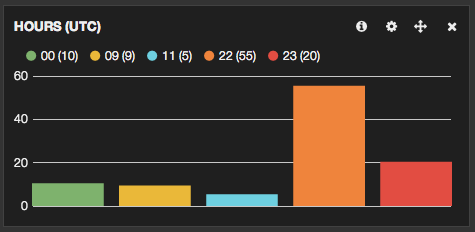
L’alerte est-elle liée à une activité particulière dans la journée ?
Cas typique ici : du load CPU sur la machine chargée de piloter les backups. Le load se produit pendant la nuit entre 22h et minuit.
Les alertes sur tel service ont-elles commencé à une date / heure précise ? Ici les remontées d’alertes “services” durant une Mise En Production
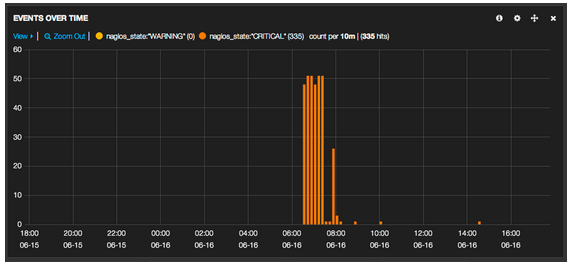
Comment évolue la qualité de sommeil de mes équipes d’astreinte ?

La totalité de la mise en place prend quelques heures et la prise en main est très rapide.
Utilisé par chacun pour l’analyse préliminaire d’un incident ou bien partagé sur grand écran lors des réunions d’équipe, ELK est un outil de choix dans l’arsenal du suivi de production.
Enfin – intérêt supplémentaire – l’outil s’adaptant très bien au troubleshooting applicatif et au suivi de performances, son utilisation commune par ingénieurs système, consultants, développeurs, … s’inscrit directement dans l’optique devops : décloisonner, partager les informations et les outils, corréler les sources (logs applicatifs, logs de monitoring, logs http, … ) pour une amélioration continue de la qualité de service.