
Spring I/O 2023 took place in Barcelona last May.
As always, the event featured several talks discussing the new features introduced in the latest versions of Java, Spring, Spring Boot, etc…
Among these talks was one focused on Spring Batch providing a comprehensive overview of its main features and changes in Spring Batch 5. The presentation was delivered by Mahmoud Ben Hassine whom you might know if you ever had a question about Spring Batch, he answers a lot of them on Stack Overflow.
https://medium.com/media/cd77114ff7e3064011b1cc99932777e6/href
In this article we will create a new batch using Spring Batch 5. It will use some of the new features presented in the talk, but the main purpose of this batch will be to showcase how we can use classifiers in Spring Batch.
The classifier integration with Spring Batch is not new, it was first introduced in Spring Batch 2. However, I only recently discovered it and struggled a little bit to find comprehensive examples. In this article we will see the main goal of classifiers in Spring Batch, and how to use them in a small demo project.
Use-case
Purpose of classifiers
The main purpose of classifiers is to handle different scenarios based on our input data. By input data I don’t mean the parameters you might retrieve before launching your job, but the data you are processing inside your job.
The textbook scenario for using Spring Batch is like this:
- reading data (from a file, a database, somewhere else) using an Item Reader
- processing it using an Item Processor: this is the step where you might transform your data or validate it
- writing the data (in a file, a database, somewhere else) using an Item Writer.

A case that I encountered which may be quite common, involves the need to process and/or write our data differently depending on what was retrieved in the reader.
For example you might want to write your data to different files based on some tag associated with each item. Alternatively, you may need to retrieve additional data in certain cases before calling your writer.
By incorporating a classifier, it becomes possible to handle these different scenarios. For example if we are using a classifier on writers it would look like this:
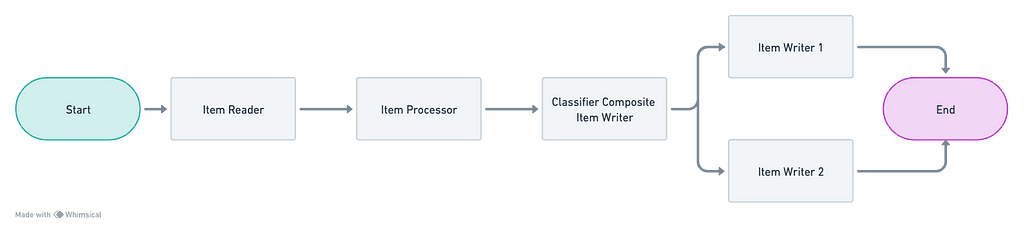
We will explore what is a ClassifierCompositeItemWriter afterwards in the demo project. However, you can already anticipate from the schema that it will classify the items and send them to either “writer 1” or “writer2” based on a condition.
Similarly, the same feature exists to classify the items before sending them to processors.
Real life example
In my current project, we had to develop a batch that each day reads data about vehicles from an XML file, and then sends this data to a web-service to synchronize the changes from the file with a database.
The XML file contains information about all the vehicles from the previous day, with a flag to indicate if each vehicle should be deleted or created/updated (creation and update are handled the same way).
The treatment for each of these cases is very different.
- for a vehicle to delete we need to retrieve its identifier and call a delete endpoint
- for a vehicle to create/update, the workflow is more complex: we need to call a web-service to upload some pictures, retrieve all the data about the vehicle, validate the data and map it to another format, and finally send it to a create/update endpoint.
A simple way to handle this case would be to handle both cases in our processor with pseudo-code like this:
public class MyProcessor implements ItemProcessor<VehicleInput, ProcessedVehicle> {
@Override
public ProcessedVehicle process(@NonNull VehicleInput item) {
if (item.status() == TO_DELETE) {
//process data to delete and return what is needed for writer
} else {
//process data to create/update and return what is needed for writer
}
}
}
And of course we would need to do the same for the writer:
public class MyWriter implements ItemWriter<ProcessedVehicle> {
@Override
public void write(Chunk<? extends ProcessedVehicle> vehicles) {
for (var vehicle: vehicles) {
if (vehicle.status() == TO_DELETE) {
//delete the vehicle
} else {
//create/update the vehicle
}
}
}
}
However, there are some downsides to this strategy:
- the code can become hard to read: if we rely solely on functions to handle each case, the classes might get big. And in theory we might have more than 2 cases to handle
- it would be harder to combine processors/writers: one of Spring Batch features is to be able to combine several processors or writers, the data will go through each one consecutively. However some of them might be specific to one of the two cases (for example a validation processor for the creation)
- specificities for each case could potentially impact the others: for example if we introduce a new field to synchronize to our vehicles, it might necessitate changes in the “delete” code even though we only need the identifier of the vehicle for this scenario
- testing might be bothersome: like any code that handles numerous tasks simultaneously, it might be easier to overlook testing certain cases and more challenging to understand the purpose of each individual test.
Using classifiers will help with all of these pain points. Let’s see how we can use them is a small project.
Demo project
Introduction
You can find the code for this project here : https://github.com/mariebnst/pet-classifier-demo.
In this article, I won’t delve into the intricacies of how to set-up a Spring Batch project from scratch and I might skip the explanation on some files. So feel free to check the code at any time if you think some key information is missing.
The use-case for this project is very similar to the real life one I presented but with a different functional context.
This batch would be used in a fictional pet adoption center. During the day, the center’s employees would update a spreadsheet based on the arrivals and departures of each pet, and during the night that spreadsheet would be synchronized with the company’s database.
Depending on a flag associated with each line of the input spreadsheet we will create, update, or delete the matching pet in the database.
Database
For this project we are using an embedded database with hsqldb. To integrate it, we need to add the following dependency to the build.gradle.kts file:
dependencies {
runtimeOnly("org.hsqldb:hsqldb")
...
}
There is only one table in the database, it is the pet table described in the schema-all.sql file:
CREATE TABLE IF NOT EXISTS pet (
id UUID NOT NULL,
name VARCHAR(250) NOT NULL,
status VARCHAR(30) NOT NULL,
species VARCHAR(250) NOT NULL,
PRIMARY KEY (id),
CONSTRAINT name_unique UNIQUE (name)
);
As you can see, there are 4 mandatory fields in the table:
- the id
- the name of the pet, which is unique
- the status: their current adoption status, based on enum values
- the species: could be “cat”, “dog”, or anything else.
There are 4 possible values for the adoption status:
public enum AdoptionStatus {
NEW,
WAITING,
AVAILABLE,
ADOPTED
}
- NEW means the pet has just arrived and is not yet available for adoption
- WAITING means someone is already interested, and is waiting to meet it
- AVAILABLE means the pet is available for adoption, you can ask to see it if you are interested
- ADOPTED means the pet has been adopted and is not available anymore.
Reader
As explained earlier, this batch has to read data from a spreadsheet and update the database.
So the first step is to create a reader that would read each line of the CSV spreadsheet in the BatchConfiguration class:
@Bean
public FlatFileItemReader<PetCsvLine> csvReader() {
return new FlatFileItemReaderBuilder<PetCsvLine>()
.name("pet-item-reader")
.resource(new ClassPathResource("sample-data.csv"))
.linesToSkip(1)
.delimited()
.names("name", "status", "species")
.fieldSetMapper(new RecordFieldSetMapper<>(PetCsvLine.class))
.build();
}
As you can see, we used the FlatFileItemReader feature to declare a reader that will read each line of the sample-data.csv file and map it to a PetCsvLine:
public record PetCsvLine(
String name,
AdoptionStatus status,
String species) {
}
To make it easier we are using a hard-coded CSV file, but in a real-life project we would probably have to retrieve it through one of the batch parameters.
This is what the sample-data.csv file looks like:
https://medium.com/media/790125b9ec3336d09af1cf0f3e6e3a55/href
It is very similar to the database entity, minus the id. As it is supposed to be a spreadsheet handled by human beings, the ids could be confusing to them.
Processors
For the processor part, we have to think about the transformation of our input data to make it easy to use in the writers.
There are three cases:
- if the status is NEW, the pet doesn’t exist in the database. So we need all the data to be able to insert it in the database: its name, its status (NEW), and its species
- if the status is AVAILABLEor WAITING, the pet already exists in the database. Its name and species have not changed, only its status has changed. So we need its name to be able to identify it, and its new status to be able to update it in the database
- if the status is ADOPTED, the pet should be deleted from the database. So we only need its name, to identify it.
We are going to declare three classes to handle each of these transformations, and pair each one with its own processor.
For all of them, we can already see that we need the name of the pet. So let’s first declare an abstract class PetAction containg the name:
public abstract class PetAction {
protected String name;
}
New pet processing
We are going to add the PetToCreate class containing all the data we need to create a new pet. It extends the PetAction class:
public class PetToCreate extends PetAction {
private AdoptionStatus status;
private String species;
}
Now we are going to add the matching processor NewPetProcessor that will map one CSV line from the input file to a PetToCreate object:
@Component
public class NewPetProcessor implements ItemProcessor<PetCsvLine, PetToCreate> {
@Override
public PetToCreate process(@NonNull PetCsvLine item) {
return new PetToCreate(item.name(), item.status(), item.species());
}
}
Updated pet processing
We are going to do the same for the pets that need a status update. First we are adding the PetToUpdate class:
public class PetToUpdate extends PetAction {
private AdoptionStatus status;
}
And the UpdatedPetProcessor:
@Component
public class UpdatedPetProcessor implements ItemProcessor<PetCsvLine, PetToUpdate> {
@Override
public PetToUpdate process(@NonNull PetCsvLine item) {
return new PetToUpdate(item.name(), item.status());
}
}
Adopted pet processing
And finally, we are adding the classes for the “adopted” status. The PetToDelete class:
public class PetToDelete extends PetAction {
}
And the AdoptedPetProcessor:
@Component
public class AdoptedPetProcessor implements ItemProcessor<PetCsvLine, PetToDelete> {
@Override
public PetToDelete process(@NonNull PetCsvLine item) {
return new PetToDelete(item.name());
}
}
Classifier Processor
Now that we have all our processors ready, we need to be able to call the right one based on the CSV line data.
First, we are going to add a new class implementing the Classifier interface. This interface is not specific to Spring Batch. According to the documentation it gives you the ability to:
Classify the given object and return an object of a different type
The documentation explains that there are already some pre-defined classes implementing this interface: PatternMatchingClassifier, SubclassClassifier, etc. We are going to use one of them for the writers part but for now let’s declare our own implementation in the PetProcessorClassifier class:
@Component
public class PetProcessorClassifier
implements Classifier<PetCsvLine, ItemProcessor<?, ? extends PetAction>> {
private final ItemProcessor<PetCsvLine, PetToUpdate> updatedPetProcessor;
private final ItemProcessor<PetCsvLine, PetToDelete> adoptedPetProcessor;
private final ItemProcessor<PetCsvLine, PetToCreate> newPetProcessor;
public PetProcessorClassifier(ItemProcessor<PetCsvLine, PetToUpdate> updatedPetProcessor,
ItemProcessor<PetCsvLine, PetToDelete> adoptedPetProcessor,
ItemProcessor<PetCsvLine, PetToCreate> newPetProcessor) {
this.updatedPetProcessor = updatedPetProcessor;
this.adoptedPetProcessor = adoptedPetProcessor;
this.newPetProcessor = newPetProcessor;
}
@Override
public ItemProcessor<PetCsvLine, ? extends PetAction> classify(PetCsvLine petLine) {
return switch (petLine.status()) {
case NEW -> newPetProcessor;
case ADOPTED -> adoptedPetProcessor;
case WAITING, AVAILABLE -> updatedPetProcessor;
};
}
}
There is only one method to implement: classify. This method takes a PetCsvLine item as its argument and returns one of the processor we previously declared based on the item’s status.
Declaring your own implementation of a Classifier gives you a lot of flexibility. You can chose which processor to use based on any condition or combination of conditions on the input data.
We need one last step for the processor part. We still haven’t properly declare a processor to use in the batch configuration class, only the reader is defined for now.
Spring Batch gives us the ability to declare a processor using a classifier with the ClassifierCompositeItemProcessor class. We can add it to the BatchConfiguration class:
@Bean
public ClassifierCompositeItemProcessor<PetCsvLine, PetAction> petProcessor(
Classifier<PetCsvLine, ItemProcessor<?, ? extends PetAction>> processorClassifier
) {
return new ClassifierCompositeItemProcessorBuilder<PetCsvLine, PetAction>()
.classifier(processorClassifier)
.build();
}
This is what the process looks like after this step:
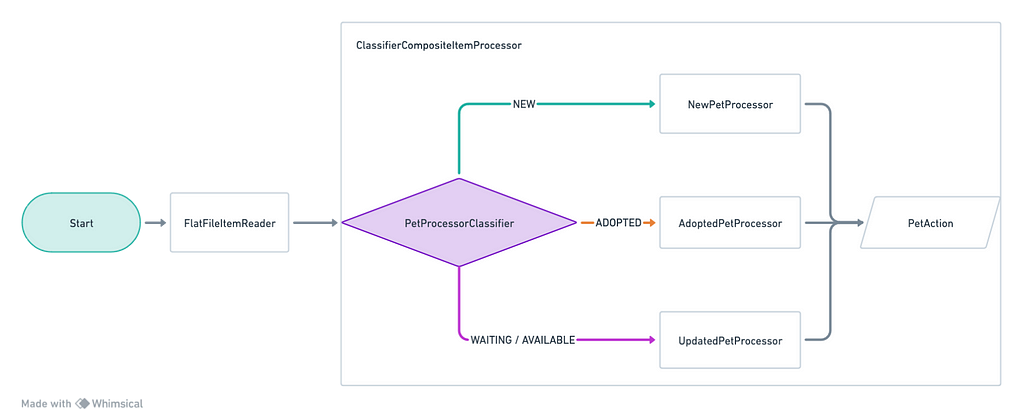
Writers
For the writers, the steps will be roughly the same as for the processors.
On a side note — in this example, we are using classifiers on both processors and writers for demonstration purposes. However, they are completely independent. You could declare a classifier on processors and use a single writer, and vice-versa.
Before creating the writers, we will need to be able to execute some operations on the database to create, update, or delete data. A PetService is created to handle all of these operations. I will not explain the code in this article but feel free to check it, we will simply assume it exists.
Let’s create three writers to handle each case:
@Component
public class CreatePetWriter implements ItemWriter<PetToCreate> {
private final PetService petService;
public CreatePetWriter(PetService petService) {
this.petService = petService;
}
@Override
public void write(Chunk<? extends PetToCreate> pets) {
pets.forEach(petService::createPet);
}
}
@Component
public class DeletePetWriter implements ItemWriter<PetToDelete> {
private final PetService petService;
public DeletePetWriter(PetService petService) {
this.petService = petService;
}
@Override
public void write(Chunk<? extends PetToDelete> pets) {
pets.forEach(petService::deletePet);
}
}
@Component
public class UpdatePetWriter implements ItemWriter<PetToUpdate> {
private final PetService petService;
public UpdatePetWriter(PetService petService) {
this.petService = petService;
}
@Override
public void write(Chunk<? extends PetToUpdate> pets) {
pets.forEach(petService::updatePet);
}
}
As you can see, each one writes items of the specific types returned by our three processors. So for our writer classifier we have the opportunity to use a SubclassClassifier.
It is defined like this in the BatchConfiguration class:
@Bean
public SubclassClassifier<PetAction, ItemWriter<? extends PetAction>>
writerClassifier(ItemWriter<PetToDelete> deletePetWriter,
ItemWriter<PetToCreate> createPetWriter,
ItemWriter<PetToUpdate> updatePetWriter) {
var typeMap = Map.of(
PetToDelete.class, deletePetWriter,
PetToCreate.class, createPetWriter,
PetToUpdate.class, updatePetWriter
);
return new SubclassClassifier<>(typeMap, null);
}
To configure this classifier, we have to declare a Map that has:
- for keys: classes extending PetAction
- for values: the corresponding writers.
This means that for example if we receive a PetToDelete object from the processor, the deletePetWriter will be called.
We didn’t need to implement our own classifier this time because there is already one that exists specifically for this case.
And finally, just as we declared a ClassifierCompositeItemProcessor previously, we are going to add a ClassifierCompositeItemWriter using the sub-class classifier:
@Bean
public ClassifierCompositeItemWriter petWriter(Classifier writerClassifier) {
return new ClassifierCompositeItemWriterBuilder<PetAction>()
.classifier(writerClassifier)
.build();
}
The full process is like this:

Full job
Configuration
Now that we have declared our reader, processor, and writer, we are going to combine them in a step and add the job lauching this step in the BatchConfiguration class:
@Bean
public Step importPetsStep(JobRepository jobRepository,
PlatformTransactionManager transactionManager,
FlatFileItemReader<PetCsvLine> csvReader,
ClassifierCompositeItemProcessor<PetCsvLine, PetAction> petProcessor,
ClassifierCompositeItemWriter<PetAction> petWriter) {
return new StepBuilder("import-pets-step", jobRepository)
.<PetCsvLine, PetAction>chunk(100, transactionManager)
.reader(csvReader)
.processor(petProcessor)
.writer(petWriter)
.build();
}
@Bean
public Job importPetsJob(JobRepository jobRepository,
Step importPetsStep) {
return new JobBuilder("import-pets-job", jobRepository)
.incrementer(new RunIdIncrementer())
.start(importPetsStep)
.build();
}
Lauching the batch
To check if everything works as intended let’s add some data to our database with the data-all.sql file:
INSERT INTO pet(id, name, status, species)
VALUES
('a7062e05-7607-472c-afce-de9f44838add', 'Harry Pawter', 'WAITING', 'dog'),
('8477115d-f911-43bf-8d2c-82f831bb5d86', 'Frodog', 'AVAILABLE', 'dog'),
('8914192f-4aa2-48ef-8b6e-38f2708e6701', 'Meowy Poppins', 'NEW', 'cat')
;
After launching the batch with this CSV file:
https://medium.com/media/790125b9ec3336d09af1cf0f3e6e3a55/href
The database contains these items:
https://medium.com/media/a2f87f3a5d16ac18de6c0b6bad7bc36c/href
Everything seems to have work as intended: two new pets were added, two were updated, and one was removed.
Conclusion
Using classifiers in Spring Batch can be very useful if you have a process with different scenarios based on the read data.
In our demo project, the treatments were simple enough to be handled without classifiers. But as soon as you need complex treatments in each scenario, it is a lot easier to understand the code with classifiers. It’s also easier to add unit tests on each processor/writer when each one has a specific job to do.
Classifiers in Spring Batch was originally published in ekino-france on Medium, where people are continuing the conversation by highlighting and responding to this story.