

L’utilisation des “golden AMI” (Amazon Machine Image) est assez courante dans les architectures cloud basées sur les machines virtuelles, mais nécessite quelques précautions d’usage sur AWS comme nous avons pu le voir sur l’un de nos projets.
Nous travaillons depuis plusieurs années pour un opérateur télécoms sur un dispositif évènementiel saisonnier.
En résumé l’application permet à un utilisateur de générer une vidéo du Père Noël délivrant un message personnalisé au contact de son choix.
https://medium.com/media/359356045240f41f551d9989dca5b909/href
Architecture et principe de la Golden AMI
La plateforme est déployée sur Amazon Web Services et utilise une architecture assez simple, adaptée à l’aspect événementiel de l’application.
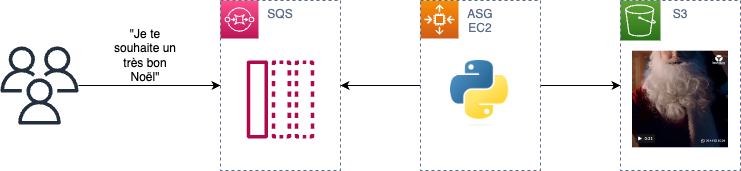
- Les demandes utilisateurs sont écrites dans une file de message SQS (Simple Queue Service) qui permet de traiter les demandes en asynchrone.
- Les messages SQS sont lus par l’application, déployée sur EC2, qui va générer le contenu audio/vidéo. L’autoscaling group EC2 ajoute ou retire des instances en fonction du volume de messages en attente dans la file SQS.
- Les contenus sont déposés sur S3 où ils sont disponibles pour la lecture
L’application à proprement parler est développée en python et nécessite de charger en mémoire un modèle d’environ 7 Go au démarrage.
Il existe 2 grands modèles (et de multiples variations) pour déployer le code applicatif et ses dépendances sur un autoscaling group, dont les instances sont par définition éphémères.
- On peut exécuter un script au démarrage de la machine virtuelle, par exemple via la user-data. Ce script va par exemple installer le serveur d’application, récupérer le code sur git, installer les dépendances, … Ce modèle offre l’avantage de la flexibilité : une modification du code n’impacte pas l’infrastructure
- On peut packager le code et ses dépendances directement dans l’image de machine virtuelle (AMI) qui sera lancée par l’autoscaling group, par exemple à l’aide de Packer. Cette méthode demande un effort supplémentaire d’automatisation du déploiement, mais offre l’avantage de l’immutabilité. C’est ce type d’image que l’on appelle une Golden AMI.
Sur un cloud public où l’on paie ses ressources de calcul à la minute, l’utilisation de Golden AMI dans un autoscaling group offre par ailleurs un gros avantage : elle réduit le temps passé à initialiser la machine virtuelle (tout est déjà installé dessus), et donc optimise le coût. En théorie…
En pratique, un résultat surprenant
Lors des phases de tests, il s’avère que le démarrage de l’application sur les instances de l’autoscaling group est bien plus lent que prévu, à configuration matérielle égale.
- Sur une machine virtuelle utilisée pour le développement l’application charge son modèle et est prête à générer des vidéos en environ 1 minute
- Sur une machine virtuelle utilisant une AMI pré-packagée qui contient l’ensemble des données ce temps est de… presque 20 minutes !
Phases de tests
Nous procédons donc à quelques tests pour mieux comprendre le problème, assistés de Datadog pour mesurer et afficher les métriques système.
La configuration des machines est la suivante :
- instance EC2 m6a.xlarge (4 vCPU, 16 Go de RAM) associée à un disque EBS de 256 Go
- AMI Ubuntu 22.04 LTS
- le setup comprend l’installation de Python, de l’agent Datadog, la copie du code et du modèle associé, et l’installation des dépendances python via Poetry
Pour chaque phase du test nous mesurons :
- l’utilisation de la mémoire du système, qui traduit le chargement du modèle de données nécessaire à la génération des vidéos
- la charge CPU de la machine, afin notamment de comprendre si le souci vient de la puissance de calcul processeur ou des I/O des machines virtuelles
- les I/O des disques EBS
1er test : machine virtuelle neuve
Ce test est effectué sur une instance EC2 fraîchement instanciée.
L’application est démarrée une première fois, et tourne quelques minutes avant d’être stoppée puis redémarrée une seconde fois.
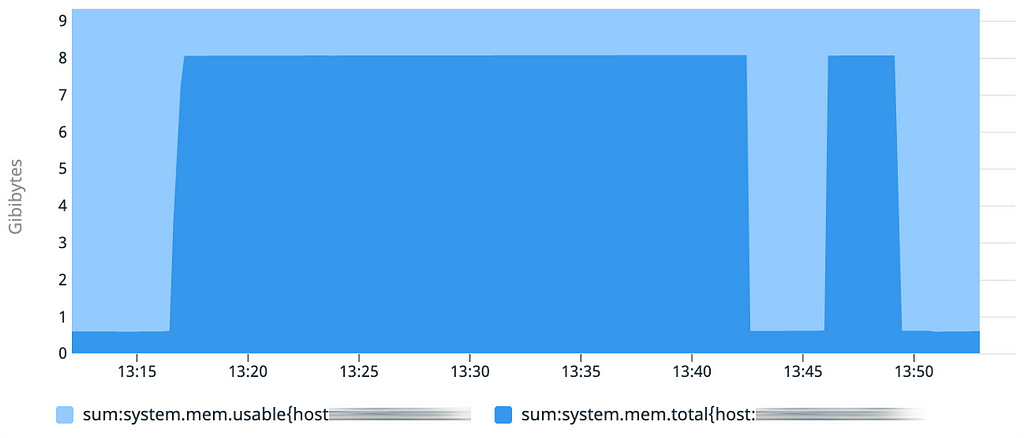
Le graphique de la consommation mémoire montre bien le chargement des données en RAM, et ce de façon rapide correspondant au temps de démarrage < 1 minute attendu. Ce comportement se répète lors des 2 démarrages successifs sur cette même machine virtuelle.
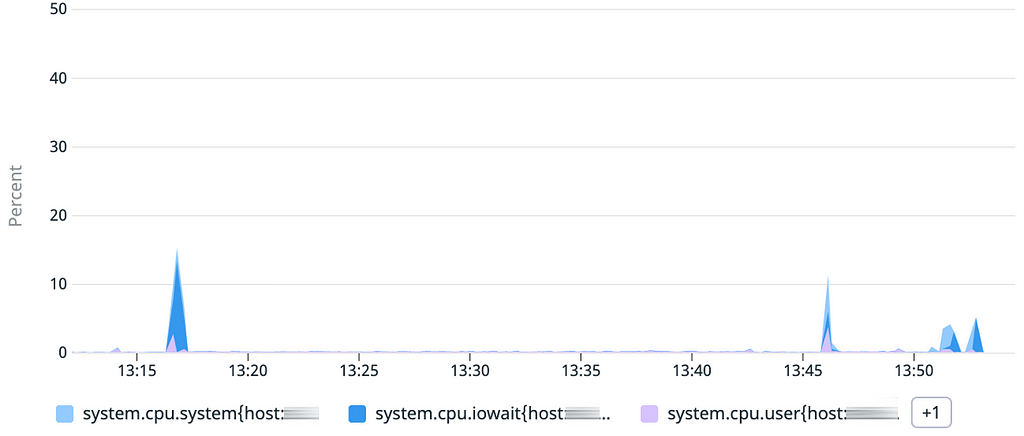
Coté CPU, pas de surprise : la principale charge est liée aux IOwait (temps passé par le processeur à attendre les disques) puisque les données sont lues sur le disque pour être chargées en mémoire.
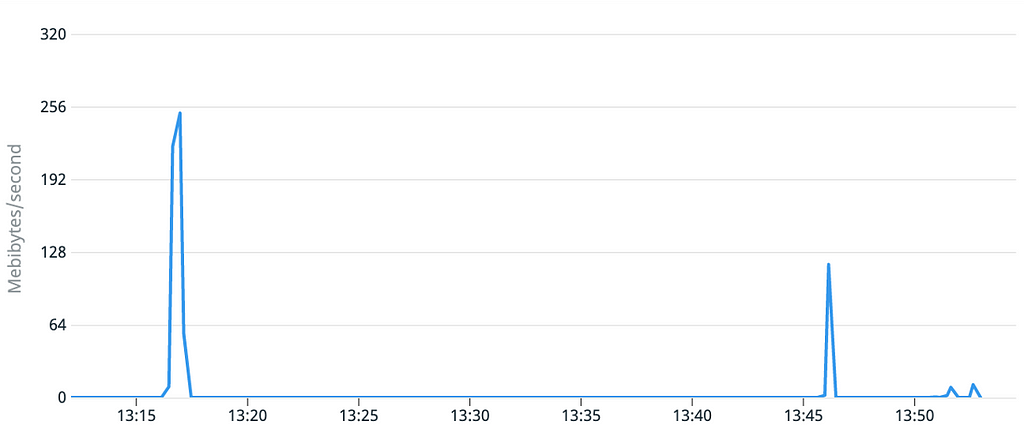
Rien de particulier à signaler sur le débit des disques, mais cette mesure nous servira de comparatif pour la suite.
2nd test : machine virtuelle instanciée depuis une AMI préconfigurée
Nous créons une AMI sur la base de la machine virtuelle utilisée pour le test précédent. Cette AMI est utilisée pour instancier une nouvelle machine virtuelle sur laquelle nous lançons de nouveau l’application 2 fois de suite.
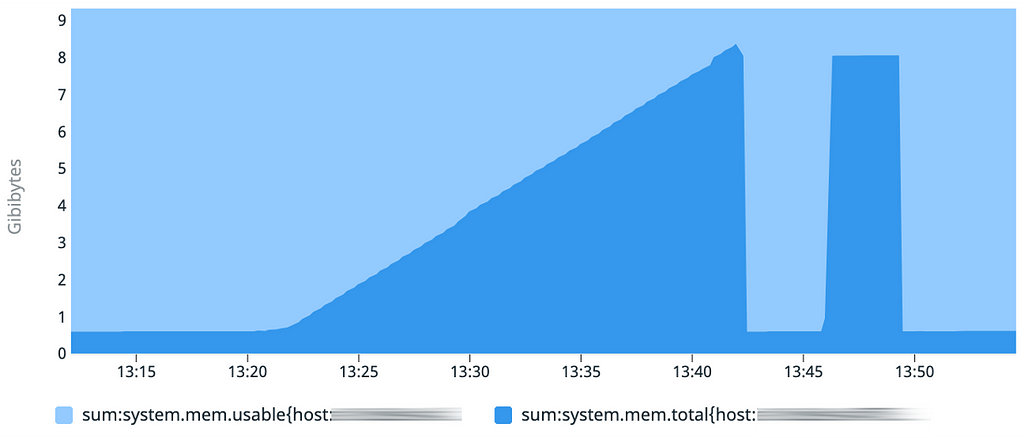
Le graphique d’utilisation mémoire met bien en évidence le temps de démarrage de 20 minutes, mais surprise, le second démarrage est lui inférieur à 1 minute. Il y a donc probablement un effet de mise en cache quelque part !
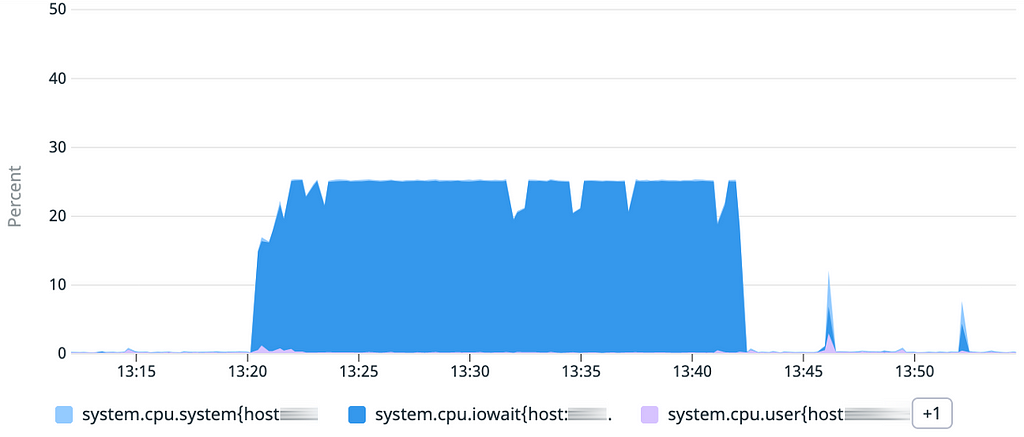
Coté CPU rien de surprenant vu le résultat précédent : la charge liée aux IOwait est constante pendant toute la durée du chargement, ce qui confirme que nous devons chercher du côté du stockage.
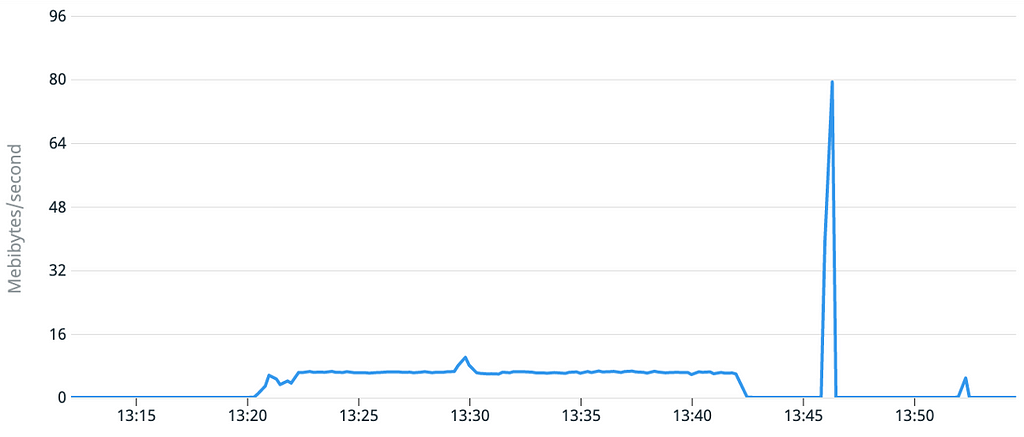
Le graphique du débit du disque est lui plus surprenant, puisque très faible pendant le 1er démarrage alors que les caractéristiques techniques du volume sont théoriquement identiques.
3ème test : mieux cerner le comportement du disque
Nous reprenons une configuration identique à celle du second test, mais interrompons le démarrage de l’application.
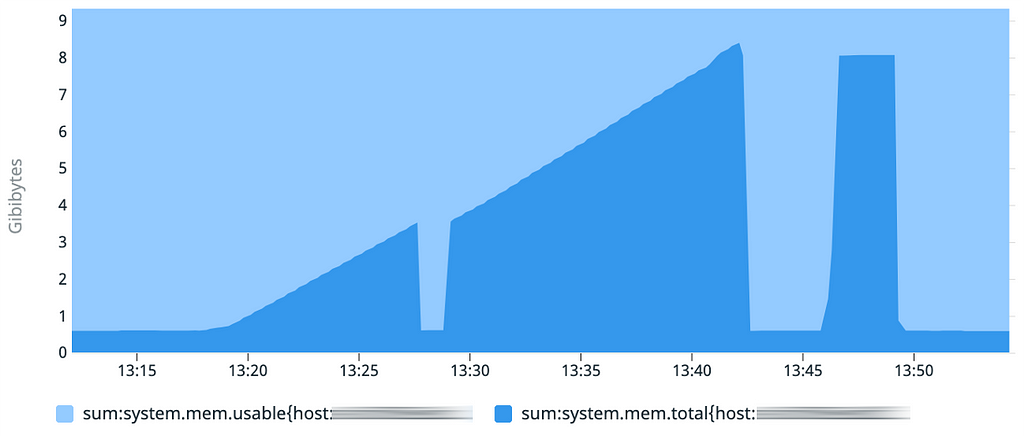
Le graphique d’utilisation mémoire est intéressant : on retrouve initialement la même pente que sur le test 2. Mais lorsque l’on stoppe le démarrage initial de l’application puis qu’on le reprend, le chargement des données qui avait déjà été effectué est bien plus rapide.
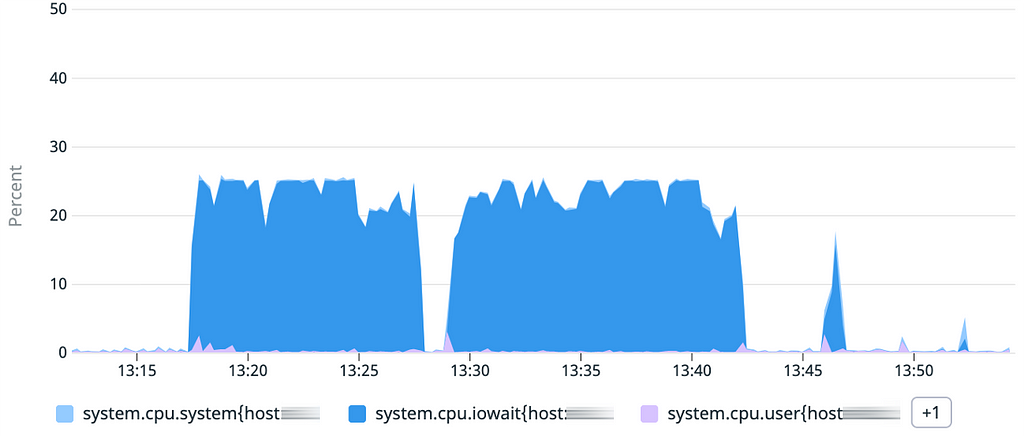
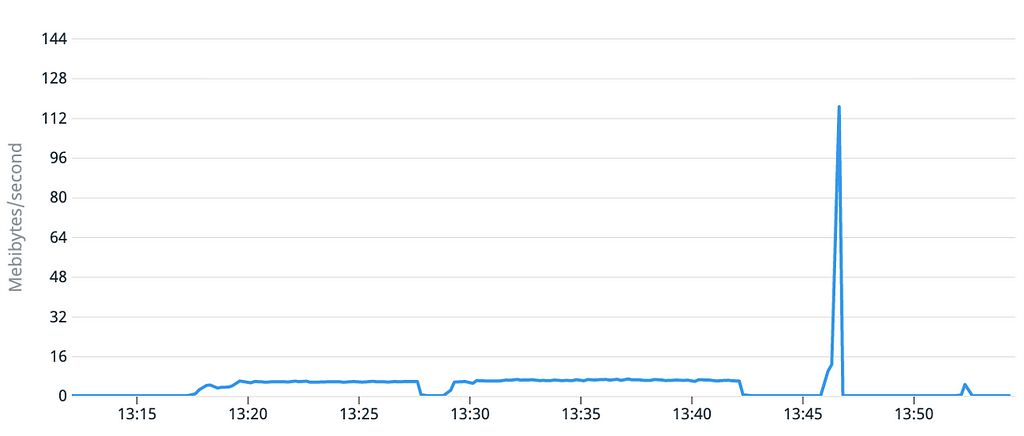
À ce stade, nous pouvons conclure que lorsque nos machines virtuelles utilisent des “golden AMI”, les performances de la lecture initiale sont très faibles, alors que les lectures suivantes sont normales.
Par opposition, sur une machine virtuelle utilisant une AMI standard et sur laquelle nous copions l’ensemble des données, pas de différence entre les performances de la 1ère lecture comparées aux suivantes.
Explication et démonstration de la solution
La solution tient à la technologie sous-jacente du stockage utilisé par AWS pour les AMI et les snapshots EBS : ces derniers sont stockés sur S3 et le système de virtualisation effectue du lazy-loading.
Ce comportement, et comment le contourner, est détaillé dans ce post de blog : https://aws.amazon.com/fr/blogs/storage/addressing-i-o-latency-when-restoring-amazon-ebs-volumes-from-ebs-snapshots/
If the volume is accessed where the data is not loaded, the application accessing the volume encounters a higher latency than normal while the data gets loaded. This higher latency due to lazy loading could lead to a poor user experience for latency-sensitive workloads.
La solution proposée par AWS est d’utiliser une feature EBS appelée Fast Snapshot Restore, ou FSR.
Cette fonctionnalité permet d’éviter le lazy-loading pour un snapshot donné, et donc d’éviter notre problème.
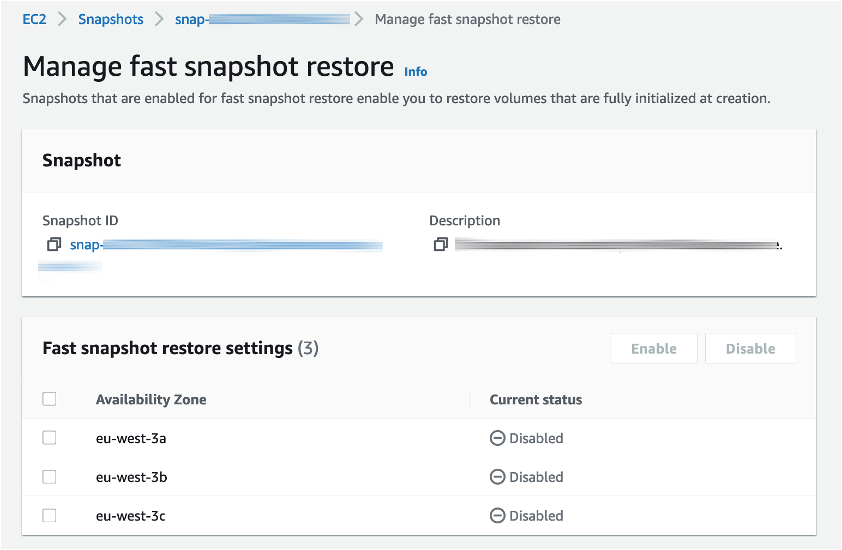
C’est une option à activer par snapshot, pour chaque zone de disponibilité ou l’on souhaite l’utiliser. Elle est facturée à la minute pour un coût mensuel de 540$ / zone de disponibilité.
À noter également que son activation n’est pas immédiate (environ 30 minutes pour notre snapshot de 256 Go).
4ème test : machine virtuelle instanciée depuis une AMI préconfigurée, avec FSR activé
Le test reste le même : nous démarrons l’application deux fois de suite pour comparer le temps d’initialisation.
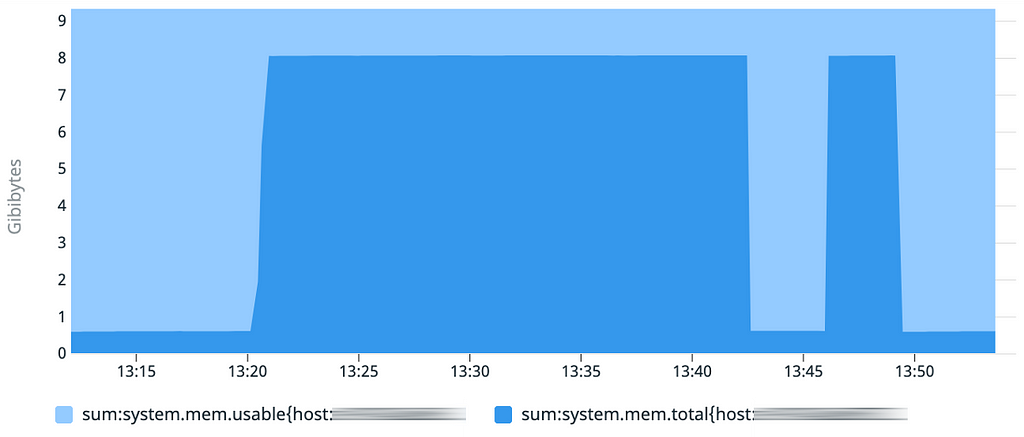
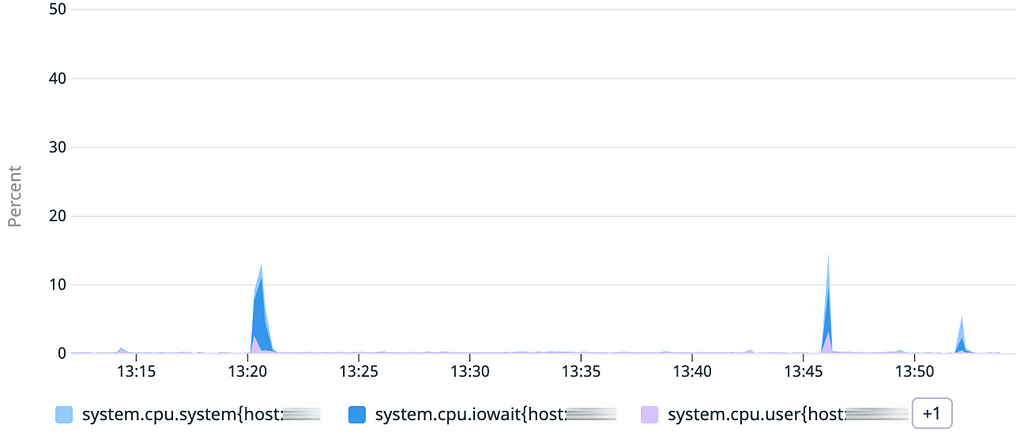
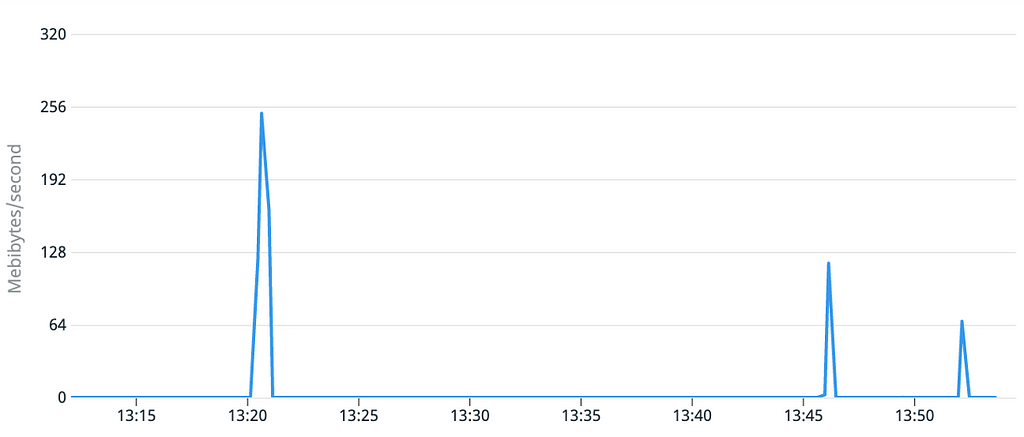
Sur les 3 graphiques, les courbes sont similaires à celles obtenues lors de notre premier test : les démarrages sont tous inférieurs à 1 minute.
Conclusions et considération de coût
Sur ce projet le traitement des vidéos est prévu pour être asynchrone : il n’y a pas de nécessité de renvoyer immédiatement le contenu à l’utilisateur.
Néanmoins, la perspective de devoir attendre jusqu’à 20 minutes pour répondre à une requête n’est pas envisageable, ni pour l’expérience utilisateur ni pour les coûts (le risque étant de payer 20 minutes d’initialisation de la machine virtuelle pour potentiellement l’éteindre 2 minutes plus tard lorsque le traitement d’une vidéo est terminé)
De ce point de vue l’option FSR est intéressante puisqu’elle permet d’envisager sereinement l’utilisation de Golden AMI en autoscaling avec des fichiers lourds à charger.
Au-delà de notre cas particulier, l’utilisation de FSR peut néanmoins se révéler coûteuse et lourde à mettre en place, surtout lorsque l’on déploie régulièrement de nouvelles AMIs.
Une alternative pourrait être de continuer d’utiliser des golden AMIs packageant le code, mais de charger le modèle (qui représente le plus gros du volume) au démarrage depuis un stockage partagé comme un volume EFS. Là aussi tout dépend du cas d’usage et du besoin d’immutabilité.
Enfin, d’un point de vue purement économique : FSR coûte 540$ / mois par AZ. Une machine virtuelle comme celle utilisée durant nos tests (m6a.xlarge + 256 Go EBS) coûte environ 170$ / mois. Suivant la volumétrie de votre projet, une alternative pourrait donc être simplement de conserver des machines disponibles 24/7, ou d’utiliser du time-based autoscaling si la charge est prédictible.
Golden AMI et Fast Snapshot Restore sur AWS was originally published in ekino-france on Medium, where people are continuing the conversation by highlighting and responding to this story.