

There are lot of things to know about search engines, and a lot too about scoring.
Let’s demystify the scoring together and try to understand how it works.
Spoiler alert: This is one out of a bunch I want to write about search engines.
Search Engine
First of all, we need to understand how does a search engine indexes things, and how it comes to a score definition in the end.
It all starts with a document. In a search engine sense, it contains all the textual information that needs to be saved for the search.
For example, if we take a book, its author, title, description and summary — all can be used to complete the document.
Then this document will go through a tokenization process.
This will be explained another time, but meanwhile you can watch this video where Benjamin Rambaud talks about tokenization in a static analysis context.
When all documents are tokenized, an inverted index is created. This index will map each token to all the documents where it appears.
The inverted index is a mapping between all the terms and the documents where they appear.
Think about a cookbook. Often, at the end of the book you’ll find each ingredient used on the book mapped to all the recipes where it’s used.
When that’s ready, a user can start querying our search engine. The user’s input is going to be translated. It will be translated into a query the search engine understands.
Now that we have the inverted index and the query, we can process the query inside the inverted index and find the related score for each document.

Scoring
Right now, the process part is just a black box, that does some stuff that we don’t understand.
It’s important to understand this black box to see where we can put our two cents.
Surely there are many search engines and each one has its own algorithm to estimate a document’s score. Let’s use ElasticSearch!
What’s a score?
A score is just a value that will help to rank the documents. They will be ranked on their level of relevance to the user’s input.
As a user I want the more pertinent results to my search to come up first. And what pertinent means will depend on the user, it is more complex than it seems.
We’ll be seeing how Elasticsearch computes it:
- First, we’ll go through the algorithm itself
- Second, we’ll popularize it with a library!
And how is it computed? 🧮
There’s an algorithm behind the search engines that will be used to compute the score.
Elasticsearch and Solr are based on Apache Lucene.
They both use the algorithm BM25 by default (since ES 5.0):
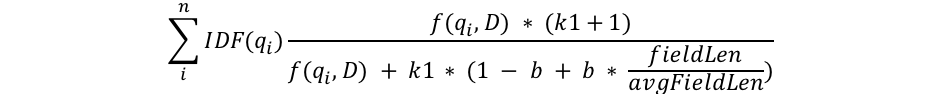

I know, you’re afraid of this equations right now (just like I was… 😛), but let’s split it into smaller parts to see what’s behind:
D: the current document we’re looking into
qi: the ith query term
N: the number of documents
n(qi): the number of documents containing qi
IDF(qi): the Inverse Document Frequency of the ith query term
The Inverse Document Frequency will try to “compute” the rarity of a term. The more a term appears in the documents, the less important the term will be and the lower the IDF gets.
fieldLen/avgFieldLen: the “how long a document is relative to the average document length”
If the length of the field is bigger than the average length, it will, in the end decrease the final score. On the other hand, when the field is smaller than the average length, it will increase the final score.
b: the parameter that controls how much effect field-length normalization should have (default value: 0,75)
k1: the parameter that controls how quickly an increase in term frequency results in term-frequency saturation (default value: 1,2)
f(qi, D): the “how many times does the ith query term occur in document D?”
The more times the query term(s) occur in a document, the higher its score will be: a document that has your name in it many times is more likely to be related to you than a document that has it only once.
Let’s put it to use in a library! 📚
Let’s see how each part works together.
You can watch this small animation (2:13 min) that will show you how terms of a query change the final score:
https://medium.com/media/7a20b5884d05679e4f3e5bf5cc445b4c/href
What can we do to change the final score, then?
Well, the expert answer will be to say that you can change the algorithm used to compute the score, maybe create your own one. But that might be overkill for now 😛
There are different approaches to change the way documents, queries are perceived by our search engine!
Just stay tuned for the second part. I will be leading you through analyzers, a tool that allows you to change the way the search engine identifies our documents.
Don’t hesitate to leave a comment if you learned something! If not here is more to read for you 😛
Read more:
- Lexical Analysis — Token
- Presentation about Static Analysis 101 or the written version
- Inverted Index
- Practical BM25 (1/3): How Shards Affect Relevance Scoring in Elasticsearch
- Practical BM25 (2/3): The BM25 Algorithm and its variables
- Practical BM25 (3/3): Considerations for Picking b and k1 in Elasticsearch
- Elasticsearch’s Similarity module
- Okapi BM25
- Elasticsearch Term frequency saturation
- Apache Lucene documentation
For more updates, visit our website and follow us on LinkedIn.
How does the score work? was originally published in ekino-france on Medium, where people are continuing the conversation by highlighting and responding to this story.