
Le cache Varnish des utilisateurs connectés : une partie de puzzle XXL.
Un reverse-proxy pour les relier tous.

{kind=link}
I. Ça varnish ?
Souvent présenté comme un “accélérateur HTTP”, Varnish est une brique logicielle de type reverse-proxy écrite en C. Il se positionne entre le client et le serveur (on parle du mode “sandwich” de Varnish), stocke la réponse du serveur et peut la retourner à nouveau s’il reçoit une autre requête du client qui mériterait la même réponse.
La requête est donc factuellement accélérée, mais il ne faut pas se méprendre en pensant que le traitement côté serveur a été rendu plus rapide. Grossièrement, on peut voir Varnish comme une anti-sèche cachée dans la trousse, on n’a pas besoin de faire appel à son cerveau, on ne réfléchit pas et on recopie ce qui a déjà été noté.
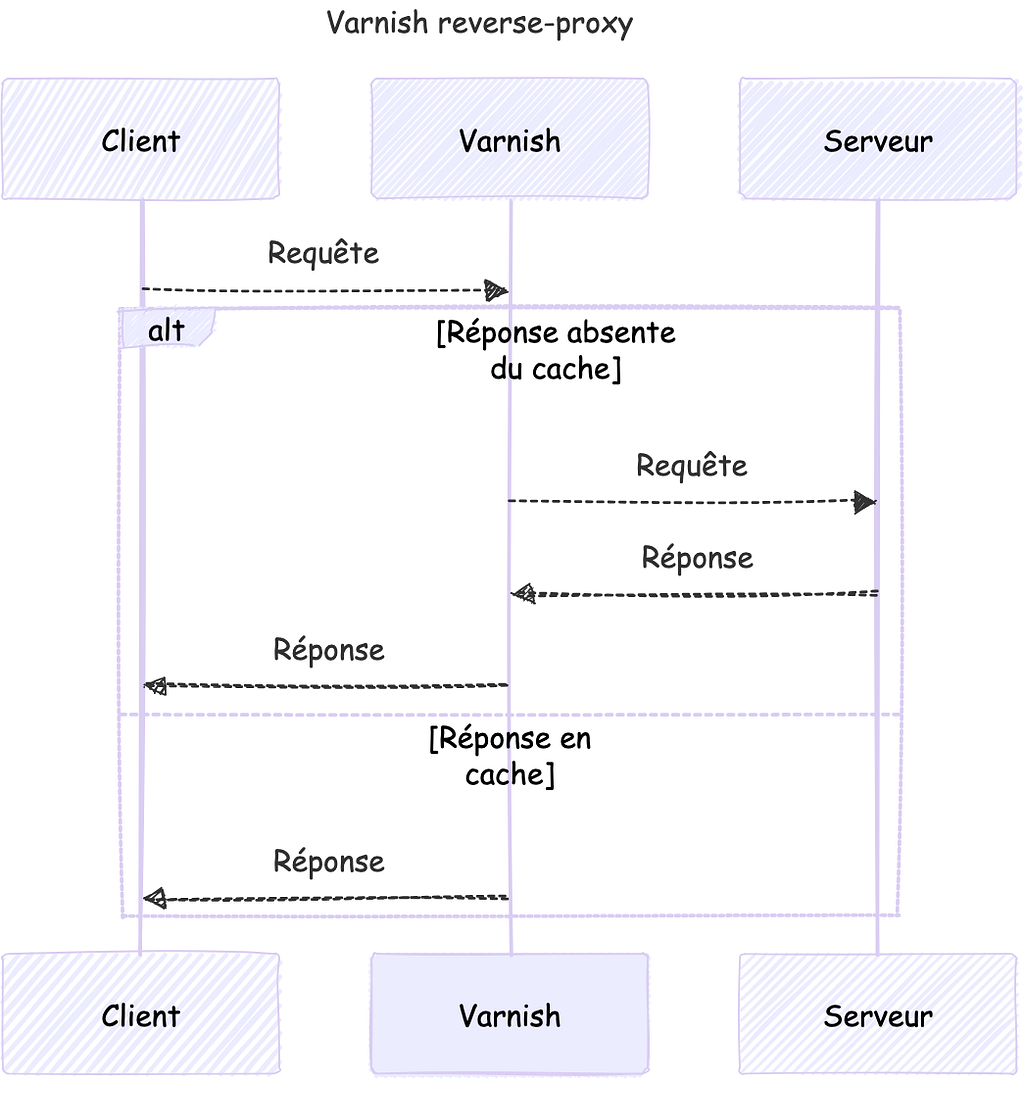
Comment Varnish parvient-il à calculer si une requête est déjà en cache ?
De façon très classique, l’outil réduit la réponse à une clé de cache ; comme dit plus haut, Varnish est un reverse-proxy, et plus précisément un reverse-proxy HTTP, il reçoit la réponse telle quelle et a accès à l’ensemble des headers à partir desquels il peut calculer la clé de cache. Nous allons voir ensemble sa méthode de calcul par défaut, puis nous verrons comment l’altérer.
À partir de là, s’il l’a déjà en stock il la retourne immédiatement, si par contre elle n’est pas présente, il passe la requête au serveur et une fois la réponse reçue elle sera stockée, réduite à une clé de cache et pourra ensuite être retournée instantanément lors de la prochaine requête.
II. Faire sa VCL
La configuration de Varnish se fait par du code (c’est là, à mon sens, un des principaux attraits de l’outil en termes de DX), le langage utilisé est le VCL (Varnish Configuration Language). Sa syntaxe ne désarçonnera pas un·e développeur·se. On est donc en mesure d’implémenter tout le paramétrage via des conditions logiques auxquelles nous sommes habitué·e·s.
Tout le flow d’exécution du VCL est le FSM (Finite State Machine), plusieurs étapes (des subroutines) sont clairement définies et nous permettent d’altérer tout le processus mis en place dès lors que Varnish reçoit une requête HTTP.
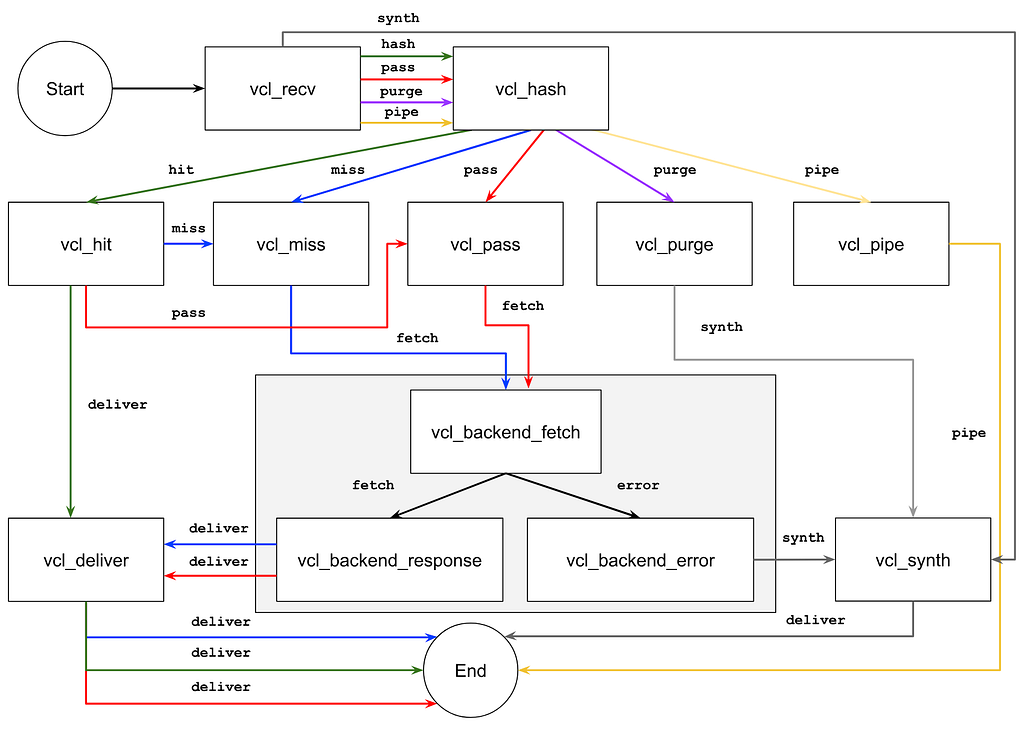
Nous n’allons pas rentrer en détail sur chaque étape du FSM, ce n’est pas le but de l’article et la documentation définit très bien chaque étape. Pour les besoins de compréhension de notre sujet, on va s’arrêter sur la subroutine vcl_hash. C’est là où le calcul de la clé de cache se fait, via du code donc.
En son sein, on peut y utiliser :
- la fonction hash_data, à laquelle on passe en argument un élément à ajouter au calcul de la clé de cache.
- l’objet req, représentant la requête HTTP parsée.
- un retour return(fail), en cas d’erreur lors du traitement. Varnish renverra aussitôt une erreur 503 au client.
- un retour return(lookup) à effectuer une fois tous les appels nécessaires à hash_data réalisés. Varnish ira alors rechercher dans son cache si une page avec la même clé de cache existe déjà.
Voici la subroutine vcl_hash telle que présente par défaut dans Varnish :
https://medium.com/media/f531bb2a60e04452c4623728077d5dc5/href
Si on s’arrête sur ce bout de code, on voit qu’on va créer la clé de chiffrement à partir de l’url et de l’hôte (si disponible dans les headers de la requête), sinon à partir de l’adresse IP du serveur.
C’est là la stratégie par défaut de Varnish : on met en cache les pages par url, pour l’ensemble des utilisateurs. Cette méthode est fonctionnelle dans le cadre de sites où les pages sont rigoureusement identiques pour l’ensemble des utilisateurs, mais elle est à exclure dès lors qu’on a une once de personnalisation.
Imaginons que, côté serveur, notre code parse la requête HTTP et renvoie une réponse dans une langue différente en fonction du header Accept-Language, on a juste une ligne à rajouter dans notre subroutine :
https://medium.com/media/4cf6c1353d80d9517764a83ceb29a761/href
On vient basiquement de réimplémenter nous-mêmes la logique du header Vary
Comment adapter cette logique à un site avec des utilisateurs connectés ?
Si on reprend notre réflexion plus-haut, Varnish est un reverse-proxy HTTP, on authentifie nos utilisateurs de façon persistante via des cookies (on prendra en exemple un cookie SESSID), et ces cookies sont envoyés à chaque requête. On y a donc accès dans notre VCL, cependant si on regarde la syntaxe on voit que tous les cookies sont envoyés pêle-mêle via un seul header :
Cookie: SESSID=298zf09hf012fh2; csrftoken=u32t4o3tb3gg43; _gat=1
Côté VCL, il est tout à fait possible d’utiliser des expressions régulières pour parser ce header, mais on peut encore faire plus simple.
Varnish nous met à disposition des extensions, les VMODs, parmi lesquels on trouve un VMOD “cookie”, présent nativement : https://varnish-cache.org/docs/trunk/reference/vmod_cookie.html
Voici un exemple issu de la documentation :
https://medium.com/media/e9bb0bb50f840ddb9045015a2bafedb7/href
Dans notre vcl_hash, on va pouvoir s’en servir ainsi :
https://medium.com/media/5b24164b721aebf07d7aa9b53c83166d/href
On progresse, on a maintenant une page mise en cache par URL et par utilisateur. Chaque utilisateur connecté aura donc son propre cache et les utilisateurs anonymes un cache commun.
Cependant, dans le cas d’un site où l’on a un système par rôle et où des grandes parties de la réponse sont communes entre plusieurs utilisateurs, il est dommage de solliciter à chaque fois le serveur pour calculer ces parties identiques de la réponse. Mais comment diviser notre page en fragments, comment mettre ces mêmes fragments dans le cache de Varnish ?
III. ESI c’était vrai ?
Les tags ESI (Edge Side Include) apportent une réponse concrète à ce besoin. Ce n’est pas une nouveauté, la RFC date de 2001. Concrètement, ce sont des blocs à intégrer dans le code HTML qui pointent vers des urls.
<!DOCTYPE html>
<html>
<body>
<esi:include src="http://..."/>
</body>
</html>
Cette syntaxe ne sera pas directement interprétée par le navigateur, il faut bien un proxy entre le serveur et le client pour faire les appels nécessaires, construire la réponse à partir des différents tags ESI présents sur la page (comme un puzzle) et la renvoyer au serveur. Varnish prend en charge ces tags, mais on les retrouve aussi dans d’autres services (Akamai ou Cloudflare pour ne citer qu’eux).
L’exemple issu de la documentation de Varnish est très parlant : https://varnish-cache.org/docs/3.0/tutorial/esi.html
<HTML>
<BODY>
The time is: <esi:include src="/cgi-bin/date.cgi"/>
at this very moment.
</BODY>
</HTML>
Le HTML entourant le tag ESI peut-être mis en cache avec un TTL long, par contre le HTML retourné par le script date.cgi doit avoir un TTL d’une minute. Côté VCL on le gère ainsi :
https://medium.com/media/e267a9cce6642b3b4db03a75a312c2ff/href
Le TTL du tag ESI est donc de 1 minute, et celui du reste, de 24 heures. Ainsi, Varnish ne rappellera le script date.cgi que si la requête est faite entre 1 minute et 24 heures plus tard.
Comment adapter cette technologie à notre besoin ? C’est ici que la partie de puzzle va commencer.
Prenons l’exemple d’une page et découpons là en différents fragments :
- ceux propres à l’utilisateur (🟥 en rouge)
- ceux communs aux utilisateurs partageant un même rôle (🟦 en bleu)
- ceux communs à l’ensemble des utilisateurs, connectés comme déconnectés (🟩 en vert)
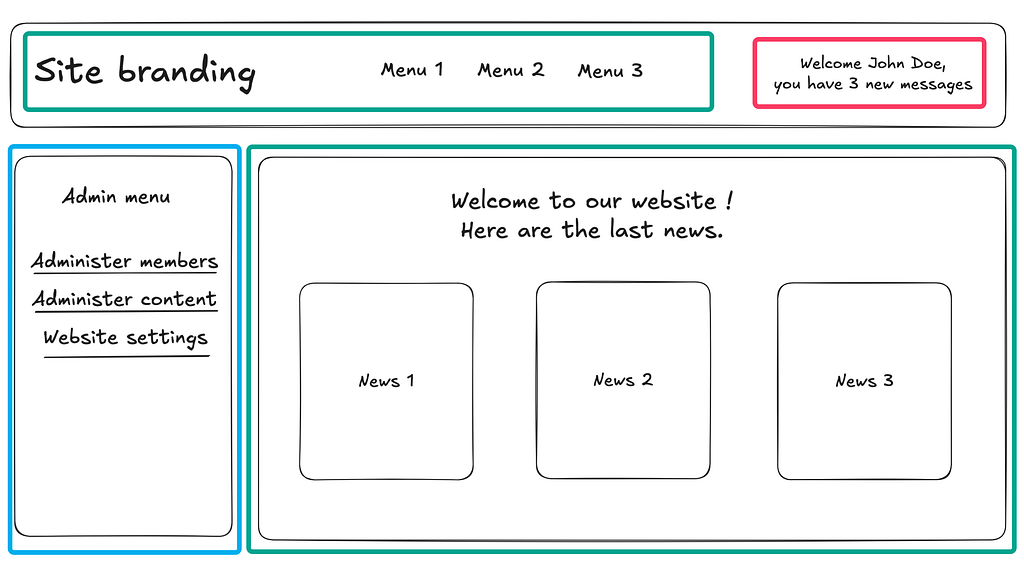
On peut donc ici envisager deux tags ESI, un pour le bloc “utilisateur connecté” en haut à droite et un pour le bloc “admin” en bas à gauche.
On a déjà vu comment définir un cache par utilisateur connecté (avec le cookie de session). On va pouvoir se resservir de la même stratégie pour établir un cookie par rôle. Côté serveur, on set un cookie en fonction du rôle, par exemple :
MYWEBSITE_ROLE_ADMIN=1
Côté code back, on peut implémenter deux routes pour nos deux tags ESI, les préfixer en fonction de si elles seront partagées ou propres à l’utilisateur et ainsi effectuer un premier tri par pattern d’URL :
'/esi/unshared/connected-user-block',
'/esi/shared/admin-block',
On va pouvoir traiter en fonction dans le VCL :
https://medium.com/media/4e159b6fa83338b91b79eec6fc512b8b/href
Et ça suffit ! Par contre niveau sécurité on n’est pas bons. Il suffit de se créer un petit cookie MYWEBSITE_ROLE_ADMIN=1 sur son navigateur pour le site en question et à nous les vues admin.
On va donc vouloir chiffrer le nom du cookie. Varnish ne prend pas nativement les chiffrements en charge, on va avoir besoin d’installer un module : https://github.com/varnish/libvmod-digest
Pour l’installation, c’est très simple. Depuis l’image Docker officielle de Varnish, il suffit d’ajouter les dépendances nécessaires à la compilation et d’exécuter le script install-vmod depuis un Dockerfile :
https://medium.com/media/9918416c4699a7e50f7e9570b1cef0df/href
Et on peut maintenant se servir des fonctions apportées par le VMOD dans notre VCL. Dans notre cas, digest.hash_sha256 suffira. On n’a plus qu’à rajouter un salt, qu’on peut définir en variable d’environnement, avec lequel on chiffrera nos clés côté serveur comme côté VCL.
https://medium.com/media/5d3e816f847940f12668e2de6f268b5b/href
La fonction std.getenv n’est pour l’instant disponible que pour la version commerciale de Varnish. Une petite ligne utilisant envsubst dans le start.sh du container fera très bien le travail.
envsubst < /etc/varnish/default.vcl.template > /etc/varnish/default.vcl
En synthétisant :
- une requête sans cookie (un utilisateur non connecté), sera mise en cache pour l’ensemble des utilisateurs.
- une requête dont l’url commence par /esi/unshared sera mise en cache en fonction du cookie de session, donc propre à un seul utilisateur.
- une requête dont l’url commence par /esi/shared et avec un cookie de rôle approprié sera mise en cache en fonction de ce cookie et sera donc partagée entre tous les utilisateurs bénéficiant de ce rôle.
Il est bien sûr largement possible d’intégrer différents rôles avec d’autres cookies et de chiffrer en fonction.
IV. Conclusion
La méthode que nous venons de voir agrège plusieurs outils mis à notre disposition en tant qu’ingénieur·e·s backend :
- les cookies
- le reverse-proxy HTTP Varnish
- les tags ESI
Ces éléments font partie des outils du web depuis très longtemps, à nous de savoir les utiliser au mieux selon les besoins. D’une façon générale, la connaissance d’outils éprouvés doit nous importer, car notre rôle en tant qu’ingénieur·e·s n’est pas de proposer la solution la plus récente ni la plus en vue, mais bien celle qui répond le mieux aux besoins de nos utilisateurs finaux.
Cette solution est adaptée à un contexte. D’autres façons de faire seraient tout à fait adaptées dans d’autres cas. Il serait par exemple envisageable de charger les blocs en AJAX et d’utiliser les leviers de mise en cache mis à disposition par le protocole HTTP (Cache-Controle, Etag, Last-Modified) qui, en stockant les pages sur le navigateur de nos utilisateurs, pourraient tout à fait répondre au besoin, mais de façon moins modulaire. En effet, des utilisateurs connectés ne pourraient pas partager le même cache, de plus le protocole HTTP ne prend pas en charge nativement l’invalidation de tags et, pour un backend en souffrance, le simple calcul d’un Etag ou d’un Last-Modified peut déjà être trop long. Les contextes sont multiples, les solutions aussi.
De même, cette méthode a ses limites, dans le cas d’un site avec une multitude de rôles selon les pages, trop de cookies seraient à mettre en place et pourraient mettre en difficulté les navigateurs comme les CDN.
Concluons en nous rappelant qu’il n’y a jamais de solution miracle et que le pragmatisme reste toujours notre meilleur allié.
Suivez les actualités d’ekino sur notre site internet et sur LinkedIn.
Le cache Varnish des utilisateurs connectés: une partie de puzzle XXL. was originally published in ekino-france on Medium, where people are continuing the conversation by highlighting and responding to this story.