
Retour sur la conférence de Benoit Viguier, présentée le 13 octobre 2022 dans le cadre du forum PHP de l’AFUP.

Benoit Viguier a débuté sa conférence par une des problématiques les plus courantes dans l’informatique : celle de normaliser un processus, créer un standard qui soit unique pour tout le monde. En effet, très souvent, en voulant créer un standard qui regroupe et améliore l’existant, on en arrive à un énième standard qui se perd parmi tous les autres.
Pourquoi avoir eu besoin de se pencher sur la création d’un nouveau standard ? Dans un monde où les micro-services sont de plus en plus utilisés par rapport aux architectures monolithiques et les échanges entre différents services se multiplient, il est devenu parfois compliqué pour les développeurs de s’y retrouver dans différentes configurations d’outils. Ce constat est d’autant plus présent dans tout ce qui concerne les métriques et autres outils d’analyse.

A priori, ça ne sera pas le cas d’Open Telemetry, qui se veut être un nouveau standard pour l’échange de données entre nos applications et les outils d’alerting — et nous allons voir pourquoi il est prometteur.
Les outils de monitoring
Mais tout d’abord, une petite piqure de rappel sur les termes principaux utilisés dans ce domaine. Commençons par la définition de monitoring : il doit nous permettre de répondre à plusieurs questions — “est-ce que ça marche” et “pourquoi ça ne marche pas” ?
Nous avons déjà tous eus à dépanner un bug en production — et bien que les outils soient là, comme LiipMonitor ou Blackfire, il n’existe pas pour le moment de norme adoptée de tous pour régulariser le processus d’échange d’informations entre nos applications et ces services, ni entre ces services eux-mêmes.
Il faut bien différencier les principaux domaines du monitoring :
Les Analytics :
Surtout lié au côté front et orienté business, les analytics simples nous apportent des données comme les visites sur notre site, mais ne vont pas vraiment être utiles en cas de panne, et sont orientées business plutôt que technique.
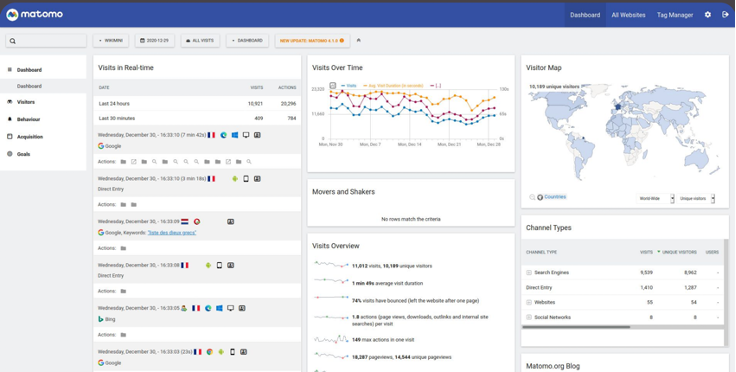
Les sondes HTTP
Elles ne sont pas intrusives, marchent partout et sont simples à mettre en place avec des scénarios variés. Mais d’un autre côté ne nous apportent pas énormément d’informations à défaut d’écrire beaucoup de scénarios différents.
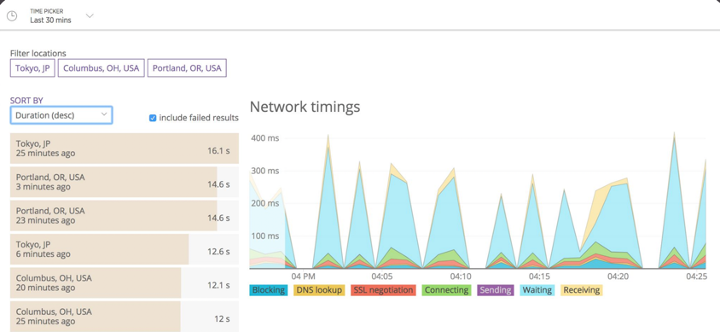
Les métriques
Les métriques, l’outil le plus visuel, agrège différentes informations sous forme de graphiques ou tables, ce qui rend possible d’observer l’évolution de notre application dans le temps. On entend souvent parler de “Golden Metrics” — qui sont définies par la performance, la charge, et les erreurs. En contrepartie, ces métriques donnent peu d’informations sur les raisons elles-mêmes des erreurs, ne pouvant que servir comme un des outils de surveillance.
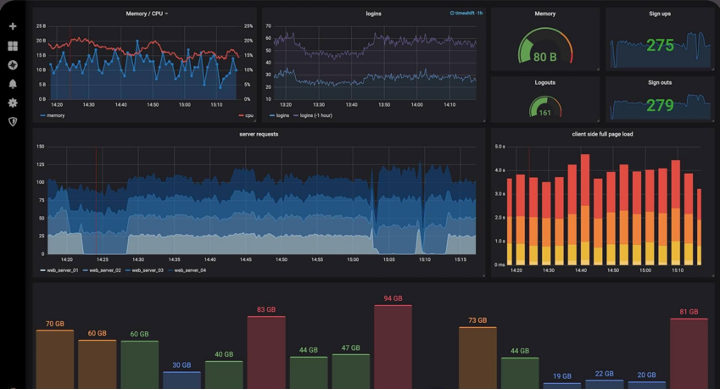
Les logs
C’est l’outil qui nous apporte le plus d’informations et le plus de détails avec le plus de simplicité, pouvant venir de pratiquement toutes les sources de notre appli — mais l’envers du décor est que le volume de données est parfois trop grand, ce qui rend complexe la recherche d’informations vraiment pertinentes.
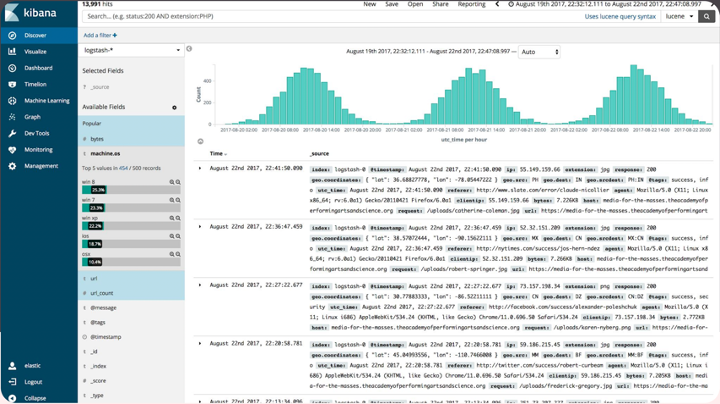
Le tracing
Enfin, le tracing, pouvant être vu comme un rayon X des processus de nos applications. Un exemple qui nous est familier est la partie “Execution timeline” dans l’onglet “Performance” dans la debug bar de Symfony, où on peut voir exactement quels services ont été appelés lors de l’exécution d’une requête, avec des données précises sur le temps que chaque processus a mis pour s’exécuter en entier. Couplé aux logs, cet outil apporte plus de contexte à nos problèmes éventuels.
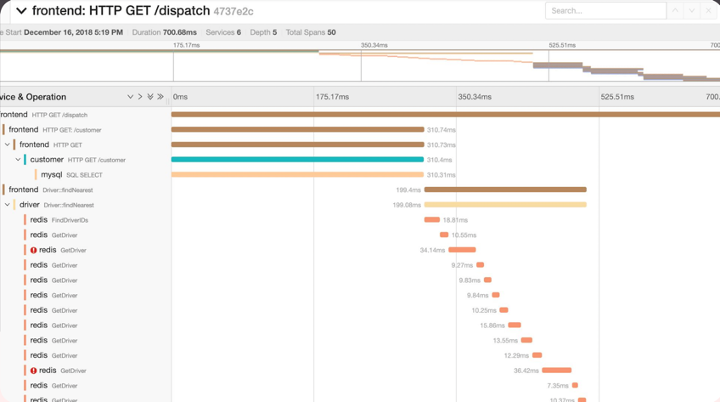
La promesse d’Open Telemetry
OpenTelemery apporte une solution unifiante. Elle propose une API indépendante du langage et du service d’analyse utilisé, qui sera un standard pour tous. Lors de la création de ce standard, 3 piliers principaux de la télémétrie ont été choisis — les logs, les métriques et les traces.
Ce nouveau standard a donc pour objectif de normaliser le transfert de données depuis notre application vers les APM (Application Performance Management), en rassemblant toutes les informations concernant les mesures depuis notre application, pour ensuite être envoyées aux APM pour analyse. Mais comment ce procédé est mis en place ?
Un collecteur proxy
La partie centrale de la structure d’Open Telemetry est le collecteur, qui fait office de proxy entre les applis de monitoring et notre backend.
Ce collecteur rassemble la logique qui décide si le backend est prêt ou non à recevoir des données. Surtout pour que les métriques ne fassent pas casser la production — il faut en effet dissocier les deux, car si nos outils de métrique cassent, on ne souhaite pas que cela ait un effet de bord sur nos applications en production.
Ce collecteur est pour le moment écrit en Go mais pourrait à terme être traduit dans d’autres langages.
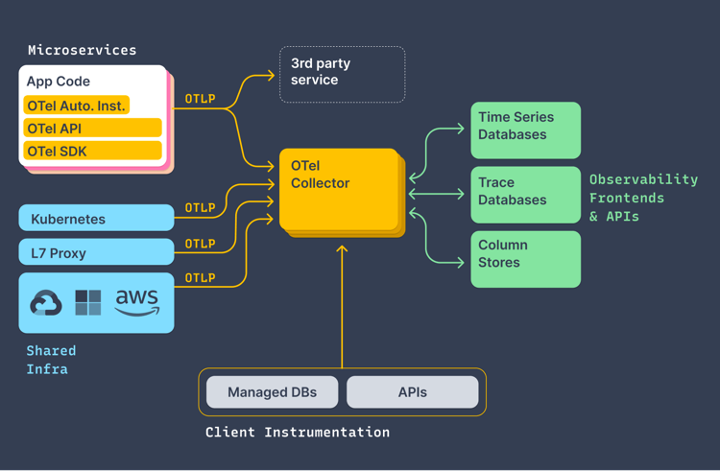
Etat d’avancement
Pour le moment, les APIs et SDKs pour le tracing et les métriques sont en état “stable”, et encore en état “brouillon” pour les logs.
Comme protocole de transport, Open Telemetry utilise gRPCS et HTTP, ainsi que le protocole Protobuf de Google (non disponible pour le PHP pour le moment) pour les payloads binaires encodés.
Un standard déjà existant depuis peu et recommandé par le W3C, le trace-context, définissant les en-têtes HTTP pour propager les informations de contexte qui permettent des scénarios de traçage parmi différents services, afin de transmettre par exemple la trace d’une erreur d’une API à une autre sera également adopté par OTel.
Sur le GitHub d’OTel, on retrouve beaucoup de dépôts divisés par langage où se trouvent les différentes implémentations du standard traduits, mais également des dépôts dédiés à l’amélioration générale d’OT, dont un que j’ai trouvé très intéressant, l’OpenTelemetry Enhancement Proposal, où dans chaque issue des propositions variées sont faites sur le futur du standard.
Open Telemetry apporte donc un standard pour les domaines principaux de la télémétrie à la façon dont php-fig apporte les PSR pour la langue PHP par exemple. En ce moment, NewRelic, Datadog ou encore Google travaillent déjà dessus ensemble, et le protocole devrait être rapidement adapté par d’autres grands acteurs de l’informatique.
En plus d’apporter beaucoup d’informations sur ce nouveau standard et de le populariser, cette conférence a permis de faire un état des lieux sur ces outils qui nous servent pour avoir une représentation de notre travail de développeurs, et surtout nous aider dans les moments difficiles quand notre code ou configuration casse — sans eux nous serions quand même bien embêtés.
Si le sujet vous a intéressé, je vous conseille de jeter un coup d’œil à la démo d’OTel ou encore à OTel en PHP.
Sources des images :
- Comics : xkcd, https://xkcd.com/
- Présentation d’OTel par Benoit Viguier (@b_viguier) au forum de l’AFUP 2022
- Documentation OTel, https://opentelemetry.io/docs/
Les outils de monitoring actuels et la promesse d’Open Telemetry was originally published in ekino-france on Medium, where people are continuing the conversation by highlighting and responding to this story.