
Vous n’êtes pas sans avoir remarqué la “petite” révolution qui secoue nombre de milieux professionnels : l’évolution exponentielle de l’IA Générative. Mais cette course à la performance a un coût écologique important, il me paraît donc intéressant dans le contexte actuel de s’intéresser à cet impact et aux alternatives. Cet article rappellera brièvement le fonctionnement des modèles d’IA Générative avant de s’intéresser aux différences entre grands et petits modèles, ces derniers pouvant bien être la clef vers un fonctionnement (un peu) plus vertueux.
Le fonctionnement de l’IA Générative et son impact écologique
C’est quoi l’IA générative ?
Les modèles d’IA générative reposent principalement sur l’architecture Transformer, introduite par Google en 2017. Ces modèles (Chat-GPT, Claude, Gemini…) servent à prédire du contenu (texte, image, vidéo, son…) à partir de données qu’on leur soumet. Pour entrainer un modèle à faire les bonnes prédictions, on lui fait “lire” des quantités énormes de données. La “lecture” de toutes ces données permet au modèle d’enregistrer des pondérations, qu’on appelle paramètres, qui lui permettent de déterminer par exemple quelle serait la combinaison de mots ayant la probabilité la plus forte de faire suite à un texte qu’on lui soumettrait en entrée.
Pour faire simple, si on fait lire l’intégralité des recettes de la page marmiton à un modèle, il aura de bonnes chances de savoir prédire la réponse à la question “Qu’est ce qu’un vol-au-vent ?” sans avoir besoin d’enregistrer le contenu de chaque page.

L’entraînement d’un modèle
Plus un modèle a de paramètres, plus il est généralement précis dans ses réponses, sur un grand nombre de sujets. Selon ce nombre de paramètres, on définit les modèles comme faisant partie des Large Language Model (LLM) ou des Small Language Model (SLM). La limite entre ces deux types de modèles n’est pas fixe et varie en fonction des sources, certains limitant l’appellation SLM à un maximum de 1 à 10 milliards de paramètres, quand certains LLM dépassent allègrement la centaine de milliards de paramètres.
Mais voilà : plus un cerveau a de neurones et de connexions à entretenir pour son fonctionnement, plus il est gourmand en énergie… Et cela se traduit directement en empreinte écologique pour les modèles.
On estime que l’entrainement d’un modèle comme GPT-3 a consommé 1287MWh d’électricité, soit l’énergie consommé en moyenne par 250 à 300 foyers français par an. Cette consommation énergétique provient principalement de deux facteurs : la puissance de calcul nécessaire pour ajuster les milliards de paramètres du modèle et le refroidissement des centres de données hébergeant ces calculs (qui sont exécutés 24h/24 pendant plusieurs semaines). En fonction du mix énergétique du pays où est implanté le centre, l’équivalent en CO2 rejeté peut varier. Pour GPT-3, dont les serveurs sont aux États-Unis, on estime un rejet d’environ 550 tonnes de CO2 soit 500 aller-retours New-York/ San Francisco pour un passager.
En comparaison, l’entraînement du SLM Llama 2–7B a rejeté “seulement” 31 tonnes d’équivalent CO2.
L’inférence des modèles
Bien entendu, l’utilisation des modèles, ou l’inférence, est également très énergivore et représente la majorité de l’impact environnemental sur le cycle de vie d’un modèle du fait de son utilisation répétée. Et l’on constate que pour une même utilisation, mobiliser les ressources d’un LLM est bien plus énergivore. D’après l’ecologits calculator de Hugging Face, une petite conversation de 400 tokens sur Ministral 3B (3 milliards de paramètres) consomme environ 1Wh d’électricité. Llama 3.1 405B (405 milliards de paramètres) consomme lui environ 95 Wh pour la même requête…
Cette différence entre LLM et SLM s’explique par la complexité supérieure intrinsèque des LLM qui mobilisent plus de paramètres à chaque requête. On peut aussi prendre en compte la méthode d’utilisation. Ces derniers sont tellement gourmands, en ressource que les faire tourner en local nécessite du matériel de pointe, on se contente donc la plupart du temps de les utiliser via API. Chaque requête transite alors par des datacenters très énergivores. De l’autre côté les SLM peuvent s’exécuter en local ou sur des serveurs plus sobres.
N’hésitez pas à utiliser le calculateur vous-même pour faire vos propres comparaisons !


Développement web augmenté : LLM ou SLM ?
Maintenant que l’on connaît l’impact environnemental de ces deux familles de modèles, intéressons-nous de plus près aux SLM. Pourraient-ils remplacer les LLM, pour un monde plus vert ?

Réponse courte : non. D’après les benchmarks disponibles, les LLM sont meilleurs que les SLM, peu importe ce que vous lui demandez. À quoi bon alors, me direz-vous ? Sur des cas d’usage bien précis (au hasard, la complétion de code), l’utilisation d’un SLM spécialisé peut potentiellement être suffisant.
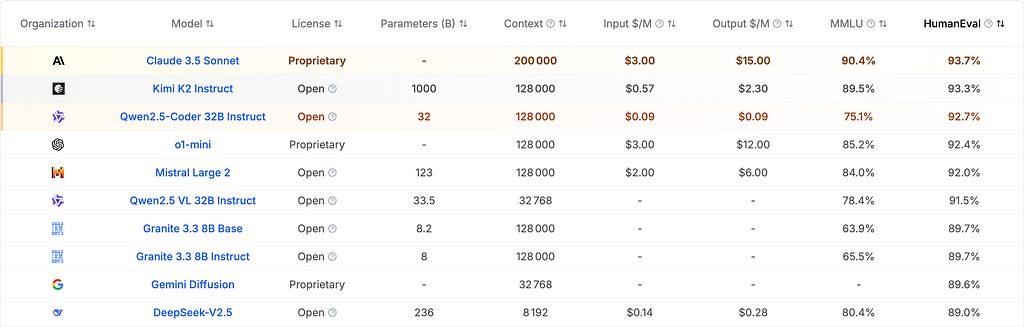
Ci-dessus le top 10 au benchmark HumanEval, qui évalue la capacité des modèles à produire du code fonctionnel en les soumettant à plusieurs tests en Python. Ce benchmark, développé par OpenAI, est aujourd’hui l’un des outils les plus utilisés pour évaluer les capacités des modèles de langage. Même s’il ne suffit pas à lui seul pour évaluer la performance globale d’un LLM en programmation, il est assez largement adopté par la communauté pour illustrer mon propos.
On observe donc que le top 5 est trusté par des modèles ayant au minimum 123 milliards de paramètres et dépassant de peu les 90% de réussite au HumanEval. Les premiers modèles à passer sous la barre des 10 milliards sont les deux Granite 3.3 de chez IBM et ils affichent environ 90% de réussite. C’est franchement pas mal et même mieux que Llama 3.1 405B qui n’est même pas dans le top 10 (il est 11ème, on ne s’enflamme pas). On remarque cependant un score bien plus faible au MMLU, un benchmark plus généraliste, alors que le top 5 n’affiche pas une aussi grosse différence de résultats entre les deux tests.
Maintenant que nous avons les performances, retour sur ecologits ! Malheureusement, le nombre de paramètres de Claude 3.5 Sonnet n’est pas public, les données sont donc une estimation. Granite 3.3 n’est pas sur ecologits, je prendrai donc un autre modèle de taille similaire en exemple. Nous prenons toujours comme référentiel la petite conversation de 400 token que nous évoquions tout à l’heure.

D’après ces résultats on peut estimer un rapport de consommation de x17 pour un gain de performance de… 4% !
Tout cela est assez enthousiasmant, cependant il faut tempérer : le choix de SLM n’est pas riche si on veut des performances au-dessus des 80% au HumanEval : pour 16 LLM (sans compter ceux dont le nombre de paramètres n’est pas publié), nous avons 5 SLM à atteindre ce score en comptant ceux d’IBM. Leur résultat a donc l’air d’être plutôt exceptionnel.
Le premier SLM du classement à descendre à 1 milliard de paramètres est Gemma 3 1B avec ses petits 45,1% de réussite. Pas assez à mon avis pour une adoption généralisée dans le monde professionnel.
En dehors de leurs performances pures, voici un récapitulatif des avantages structurels des SLM que j’ai pu recenser :
Latence réduite
Les SLM ont naturellement une latence très faible, encore réduite quand ils sont en local ce qui permet une expérience de développement plus fluide.
Coûts optimisés
- En local : éviter d’avoir recours à une API qui facture à l’utilisation permet de réduire les coûts sur le long terme.
- Par API : en général plus un modèle est petit, moins il est cher à l’inférence.
Confidentialité et sécurité
- En local : le code n’étant pas envoyé à une entité tierce, on garde un contrôle total sur le traitement des données. C’est un bon point pour votre conformité RGPD et cela peut aussi rassurer certains clients évoluant dans des secteurs très sensibles.
Fiabilité
- En local : éviter la dépendance à un service externe (de surcroit américain ??) permet de prendre la main pour assurer la continuité de sa disponibilité.
Fréquence des mises à jour
Les SLM sont mis à jour plus fréquemment car étant plus petits, le processus est moins coûteux en ressources alors qu’un LLM demande un ré-entrainement massif.
Possibilité de fine-tuner soi-même
- En local : Possibilité d’entraîner soi-même relativement facilement son SLM sur un corpus rassemblant documentation, code base de un ou plusieurs projets…
Malgré mon enthousiasme pour les SLM, il paraît difficile d’envisager de n’utiliser que des modèles de petites tailles. Cet article a montré que même s’ils peuvent être très bons dans un type de tâche, ils sont bien moins polyvalents que les LLM. Ne s’équiper que de SLM reviendrait donc à faire l’impasse sur les tâches complexes nécessitant plus de contexte que de la simple complétion de code et à gérer une multitude de SLM spécialisés dans chacune des tâches dont on a besoin pour évoluer au quotidien.
Cependant de nombreux acteurs s’activent à mettre en place des solutions hybrides. L’innovation va vers des systèmes de routage permettant de sélectionner le meilleur modèle pour remplir une tâche en fonction de critères comme sa nature, sa complexité, du coût d’inférence ou de la confidentialité nécessaire. Ce routing peut être géré par un framework spécifique ou par un modèle à part entière, qu’il soit gros ou petit. On peut donc imaginer un système qui redirigerait les prompts vers des SLM (pourquoi pas en local ou auto-hébergés) pour les tâches les moins complexes et vers des LLM cloud pour les tâches nécessitant plus de puissance.
Le développement des SLM et des solutions hybrides ne vient manifestement pas d’une envie de sobriété écologique : d’après les ressources que j’ai pu consulter, elle tient plus de l’effet secondaire bénéfique que d’un réel objectif. Le besoin de s’orienter vers des solutions plus sobres vient comme souvent du fait qu’il est nécessaire pour une entreprise d’adapter ses outils en fonction de la valeur ajoutée dégagée sur les différentes tâches : nul besoin de sortir la grosse artillerie pour des tâches simples, alors qu’il est nécessaire de bénéficier de plus de puissance pour des tâches plus ardues. Cependant je remarque que de plus en plus de sources (comme ce benchmark) n’hésitent pas à indiquer l’impact écologique des différentes solutions, ce qui montre au moins un intérêt de certains des acteurs du secteur pour cela.
À propos d’ekino
Le groupe ekino accompagne les grands groupes et les start-up dans leur transformation depuis plus de 10 ans, en les aidant à imaginer et réaliser leurs services numériques et en déployant de nouvelles méthodologies au sein des équipes projets. Pionnier dans son approche holistique, ekino s’appuie sur la synergie de ses expertises pour construire des solutions pérennes et cohérentes.
Pour en savoir plus, rendez-vous sur notre site — ekino.fr.
Sources :
https://generationia.flint.media/p/comment-calculer-vraiment-impact-carbone-de-chatgpt-climat-ia-eau
https://www.lemagit.fr/conseil/IA-generative-petit-modele-petit-bilan-carbone
https://huggingface.co/spaces/genai-impact/ecologits-calculator
https://drane-versailles.region-academique-idf.fr/spip.php?article1167
https://huggingface.co/spaces/ArtificialAnalysis/LLM-Performance-Leaderboard
https://www.vellum.ai/llm-leaderboard
https://livebench.ai/#/
https://botpress.com/fr/blog/ai-agent-routing
https://hugginggpt.space/
L’IA Générative face aux enjeux écologiques was originally published in ekino-france on Medium, where people are continuing the conversation by highlighting and responding to this story.