
Optimiser l’expérience de recherche dans un projet Symfony multilingue : le choix de Meilisearch?
C’est maintenant la norme d’avoir un moteur de recherche sur un site web avec du contenu éditorial pour favoriser l’expérience utilisateur. De nombreuses solutions plus ou moins performantes et faciles à mettre en place sont disponibles pour cette fonctionnalité.
Dans le cadre d’un projet Symfony de type éditorial, avec plusieurs sites (une vingtaine de sites correspondant à des pays et des langues différentes) et relativement peu de contenus (environs 800 contenus par site), nous cherchions à mettre en place un système de recherche qui :
- est disponible à coût réduit/optimisé
- permet d’avoir des instances différentes par environnement
- retourne des réponses rapidement
- propose un système de ranking sur plusieurs attributs
Parmi toutes les solutions possibles (Elasticsearch, Algolia, Solr…), nous avons choisi Meilisearch.

Meilisearch est une solution open source permettant de mettre en place facilement un moteur de recherche et répondant à tous nos besoins.
C’est d’ailleurs le moteur de recherche qui a été mis en place récemment par Symfony pour la recherche dans sa documentation (cf. https://symfony.com/blog/migrating-symfony-com-search-engine-to-meilisearch)
Cet article a pour but de vous expliquer comment nous avons mis en place la recherche Meilisearch dans le cadre de notre projet. La documentation de Meilisearch est très complète aussi bien sur le fonctionnement et la configuration de cette solution que sur l’API mise à disposition.
Le projet Meilisearch est bien actif, plusieurs releases ont été déployées depuis que nous avons commencé à mettre en place cette solution. Ils sont aussi très réactifs, répondant rapidement aux tickets/questions ouvertes chez eux.
Installation
Binaire ou cloud
Il y a plusieurs façons d’installer Meilisearch sur une machine (binaire, conteneur Docker…) et ça sur les systèmes d’exploitations Linux/macOS/Windows.
Il est aussi possible d’installer Meilisearch sur différents cloud providers (AWS, Azure…).
Il existe aussi une version cloud de Meilisearch avec un système d’abonnement à différentes offres selon vos besoins.
De notre côté nous avons décidé d’installer directement le binaire sur chaque machine de nos différents environnements.
Une fois installé, une API RESTful est mise à disposition pour toutes les interactions avec Meilisearch.
SDK
Meilisearch met aussi à disposition des SDKs pour un grand nombre de langages (cf. https://www.meilisearch.com/docs/learn/what_is_meilisearch/sdks)
Nous avons donc mis en place le SDK pour PHP (https://github.com/meilisearch/meilisearch-php).
Celui-ci nécessite pour fonctionner de mettre en place
- un client http
- un package implémentant la PSR-7 pour les messages http
Dans notre cas nous sommes partis sur les packages symfony/http-client et nyholm/psr7
composer require meilisearch/meilisearch-php symfony/http-client nyholm/psr7
Mais il est tout à fait possible d’utiliser d’autres packages comme indiqué dans la documentation (cf. https://github.com/meilisearch/meilisearch-php#-http-client-compatibilities)
Avec ce SDK, il sera très facile de faire les différents appels de l’API Meilisearch dans la partie backend de notre projet.
Système de API keys
Lors du lancement de Meilisearch, il est possible de passer en paramètre une master key.
Cette clé doit être une chaîne de caractères en UTF-8 de 16 octets au minimum.
./meilisearch - master-key="MASTER_KEY"
Dans le cas d’un environnement de développement, cette clé est optionnelle. Si elle n’est pas spécifiée, l’API sera alors publique et donc aucune authentification sera nécessaire pour interargir avec Meilisearch.
Dans le cas d’un environnement de production, cette clé est obligatoire sinon Meilisearch ne se lancera pas. L’API est donc forcément protégée par une authentification.
Quand vous lancez Meilisearch pour la première fois, deux nouvelles clés vont être générées:
- default search API key : cette clé permet de s’authentifier lors de l’appel du endpoint /searchde l’API Meilisearch mais ne donne pas accès aux autres endpoints de l’API.
- default master API key : cette clé permet d’accéder à tous les endpoints de l’API (sauf les endpoints /keys)
Il est aussi possible de créer/supprimer de nouvelles clés grâce aux endpoints /keys de l’api Meilisearch. Pour faire ces appels il faudra alors s’authentifier en utilisant la master key. Celle-ci par contre est fixe et ne peut pas être modifiée via l’API.
Ainsi dans un cas classique, le front d’une application utilisera une Search API Key pour lancer la recherche. Cette clé pourra sans risque être exposée dans le code du front car elle ne permet que de lancer la recherche.
Le backend lui utilisera une Admin API Key pour lancer toutes les actions plus sensibles comme la création d’index, l’indexation de document… Evidement cette clé devra rester secrète pour éviter toute mauvaise action sur Meilisearch.
Il est possible de créer un autre type de clé, appelée tenant token. Il s’agit d’une clé qui sera utilisée pour le endpoint search et qui est composée d’une search API key et d’un ensemble de critères de recherche. Il est ainsi possible de forcer dans une recherche l’ajout de filtres qui ne pourront pas être contournés et qui seront donc appliqués à la recherche.
Par exemple dans le cas d’une application médicale dont tous les documents indexés contiennent le numéro du patient, un patient avec un tenant token qui lui est propre et contenant un filtre sur son numéro, pourra lancer une recherche sur tous les documents mais ne seront alors remontés que les documents avec son numéro.
Ces différentes clés permettent donc de gérer l’accès aux différentes actions de l’API mais aussi l’accès aux différents documents.
Backend et Frontend
Dans notre application, les tâches seront distribuées entre le backend et le frontend.
- Le backend se chargera de créer, configurer, alimenter les différents indexes des différents sites.
- Le frontend aura en charge la recherche et l’affichage des résultats
Côté backend, nous avons créé des commandes Symfony qui pourront être cronées. Celles-ci créent des messages qui seront traités en asynchrone via un système de queue (cf. https://symfony.com/doc/current/messenger.html).
Le frontend pourra appeler directement le endpoint /search de l’API Meilisearch.
Mise en place d’un index
La mise en place d’un index pour la recherche se fait par une succession d’appels de l’API Meilisearch via le SDK. Nous allons créer un nouvel index, le configurer, lui ajouter tous les documents recherchables. Une fois ce nouvel index utilisable, nous allons le permuter avec l’ancien index en place. Ce système de permutation permet ainsi d’éviter toute interruption de disponibilité de la recherche. Puis nous allons supprimer l’ancien index devenu inutile.
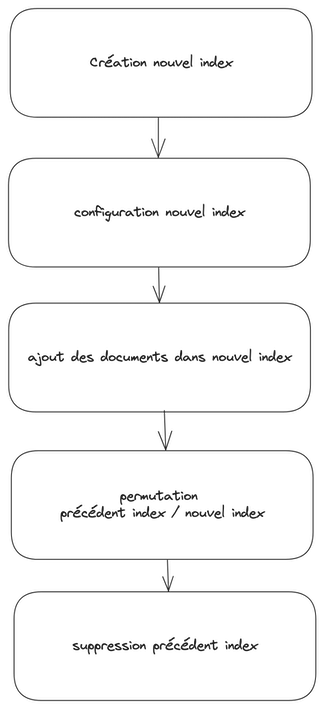
Ce processus assez simple nous suffit. Nous n’avons pas un besoin métier d’ajouter/modifier/supprimer un document dès qu’un contenu est modifié dans notre CMS. Réindexer la totalité des contenus deux fois par jour est suffisant dans notre cas et ne prend que quelques minutes par site.
Bien sûr dans le cadre d’un projet avec par exemple des articles d’actualité nécessitant une disponibilité instantanée dans la recherche, l’API permet d’ajouter/modifier/supprimer des documents unitairement. Il suffit de brancher les bons appels à l’API via les méthodes du SDK dans les différentes actions de votre CMS.
La notion de tâche
De manière générale, Meilisearch fonctionne avec un système de queue interne. Par exemple lors d’un appel API pour lancer une création d’index, une tâche est alors créée côté Meilisearch et l’API retourne un identifiant de tâche.
On peut faire un appel GET/tasks/{taskUid}pour savoir si la tâche a été traitée.
Le SDK fournit une méthode pour ça avec la possibilité de configurer le temps de retry et le temps maximum à attendre:
public function waitTask($taskUid, int $timeoutInMs, int $intervalInMs): array
{
$timeoutTemp = 0;
while ($timeoutInMs > $timeoutTemp) {
$res = $this->get($taskUid);
if ('enqueued' != $res['status'] && 'processing' != $res['status']) {
return $res;
}
$timeoutTemp += $intervalInMs;
usleep(1000 * $intervalInMs);
}
throw new TimeOutException();
}
L’exécution de notre code sera donc en attente dans cette boucle tant que la tâche n’aura pas été traitée correctement, avec une erreur ou mis trop de temps.
Dans notre code, on pourra donc chainer les appels pour créer un index, le configurer, y ajouter les documents tout en gérant les éventuelles erreurs lors des différentes actions.
Voici un exemple simple d’implémentation :
<?php
namespace AppSearch;
use MeilisearchClient;
use MeilisearchContractsIndexesQuery;
use MeilisearchEndpointsIndexes;
class SearchService
{
private const TIMEOUT = 10000;
private const INTERVAL = 1000;
private Client $client;
public function __construct(string $apiUrl, string $apiKey)
{
$this->client = new Client($apiUrl, $apiKey);
}
public function indexation(string $indexName, array $settings, array $documents): void
{
$responseCreation = $this->client->createIndex($indexName, ['primaryKey' => 'id']);
$this->waitForTask($response['taskUid']);
$responseSettings = $this->client->index($indexName)->updateSettings($settings);
$this->waitForTask($response['taskUid']);
$responseIndexation = $this->client->index($indexName)->updateSettings($settings);
$this->waitForTask($response['taskUid']);
$responseAddDocuments = $this->client->index($indexName)->addDocumentsJson($serializedDocuments);
$this->waitForTask($response['taskUid']);
}
private function waitForTask(int $taskUid): void
{
$response = $this->client->waitForTask($taskUid, self::TIMEOUT, self::INTERVAL);
if ($response['status'] === 'failed') {
throw new Exception($response['error']['message'] ?? 'Unknown error from Meilisearch');
}
}
}
Attention si on a un timeout, cela veut dire que la tâche n’est pas finie. Dans ce cas il faut envisager de l’annuler avant de relancer la séquence.
Création d’un index
On crée un index avec la méthode createIndex(string $uid)du SDK qui appelle le endpoint POST /indexes avec en paramètre l’uid (c’est une string, cela correspond au nom unique de l’index) et le champ qui servira d’identifiant dans les documents (on en reparle plus bas dans la partie ajout de documents)
Configuration d’un index
Après avoir créé un index, on doit le configurer pour répondre à nos besoins. On utilise la méthode updateSetting(string $settings)du SDK qui appelle le endpoint PATCH /indexes/{uid}/settings avec en paramètre un tableau avec la configuration.
Il y a plusieurs options de configuration, chacune correspondant à une entrée de ce tableau.
Il faut dans un premier temps connaître la structure de vos documents et tous ses champs (cf. le paragraphe ‘ajout de documents’ ci-dessous).
Voici ce tableau dans notre cas.
$settings = [
'searchableAttributes' => [
'tags',
'title',
'subtitle',
'date',
'text',
'url',
],
'rankingRules' => [
'words',
'typo',
'attribute',
'proximity',
'sort',
'exactness',
'date:desc',
],
'filterableAttributes' => [
'type',
],
'typoTolerance' => [
'disableOnAttributes' => [
'tags',
],
],
'displayedAttributes' => [
'id',
'type',
'title',
'subtitle',
'date',
'text',
'url',
],
'synonyms' => [['chaussure', 'pompe', 'soulier', 'godasse', 'grolle', 'tatane'],
'stopWords' => ['ça', 'car', 'ce'],
];
- searchableAttributes définit dans quels champs de vos documents sera faite la recherche. L’ordre de ces champs indique aussi leur priorité. Dans notre cas, les documents avec un tag correspondant à la recherche remonteront avant les contenus avec un text correspondant à la recherche.
- rankingRules définit l’ordre d’importance des règles mises en place pour la recherche. Vous trouverez la liste des règles dans la documentation (https://www.meilisearch.com/docs/learn/core_concepts/relevancy#built-in-rules)
- filterableAttributes définit les champs qui permettront de faire des filtres et des facettes. Dans notre cas, on a plusieurs types de contenus, on pourra donc faire une recherche sur un type spécifique ou classer les résultats par type.
- typoTolerance.disableOnAttributes pour désactiver la typo tolérance qui est activée par défaut. Dans notre cas, nous voulons pouvoir faire une recherche sur un tag et que seuls les contenus contenant exactement ce tag soient retournés. Nous désactivons la typo tolérance sur ce champs uniquement.
Il existe d’autres réglages pour modifier la typo tolérance comme minWordSizeForTypos qui permet d’ajuster le nombre d’erreurs autorisées en fonction de la longueur du mot. - displayedAttributes définit les champs qui seront remontés dans les résultats.
- synonyms contient une liste de synonymes.
- stopWords contient une liste de mots dont la recherche ne doit pas ternir compte
Pour les synonymes et les stop words, nous avons récupéré des fichiers pour chaque langue contenant des listes de mots (ce sont des exemples dans le code ci-dessus car il y en a bien trop). Nous ajoutons le contenu de ces fichiers lorsque nous construisons le tableau de settings ainsi que certains synonymes spécifiques à notre métier.
La liste complète des réglages est évidement disponible dans la documentation https://www.meilisearch.com/docs/learn/configuration/settings
Ajout de documents
La méthode addDocumentsJson(string $indexes) du SDK appelle le endpoint POST /indexes/{uid}/documents avec en paramètre le json contenant l’ensemble des documents sérialisés.
Tous les documents doivent avoir le même format. Nous avons mis en place un modèle commun à tous nos types de contenus. Il contient tous les attributs qui permettront d’effectuer la recherche et tous les champs que nous souhaitons afficher dans les résultats.
Dans notre cas, voici notre modèle (il est très simple) :
$document = [
'id',
'type',
'tags',
'keywords',
'title',
'subtitle',
'date',
'text',
'url',
];
- id est l’identifiant du document, doit être unique. Dans notre cas il s’agit de la concaténation du type de contenu avec son id pour éviter tout recoupement d’id entre les différents types.
- type est une string correspondant au type de document. Il permet de faire un filtre sur le type dans la recherche et de regrouper les résultats par type.
- tags est un array contenant des codes précis. Il servira à faire une recherche sur des codes de manière exacte.
- keywords est un array contenant des mots clés. Il servira à faire une recherche à partir du/des mots saisis de manière tolérante.
- le reste des champs est assez classique
- tous nos types de contenus n’ayant pas tous les champs, certains seront donc passés à null ou sous forme d’array vide.
A noter que Meilisearch s’adapte au type de valeur passé dans chaque champ. Il faut juste que ce soit un type Json (string, array, date, integer, null, objet..) et rester cohérent entre documents.
Il est aussi possible de passer dans un array avec des sous array contenant d’autres valeurs ou même un objet. Cela peut être le cas par exemple pour passer un tableau de liens, un objet représentant un auteur… Ils seront alors restitués tels quels dans les résultats.
Attention, il y a une limite de taille pour les valeurs de champs de 65535.
Dans notre cas nous utilisons du Json mais il est aussi possible d’utiliser du csv.
Permutation d’indexes
La méthode swapIndexes(array $indexes) du SDK appelle le endpoint POST /swap-indexes avec en paramètre un tableau de couple d’indexes à permuter.
Attention lors d’une permutation de 2 indexes, les uids sont permutés. Dans notre cas, nous avons créé un nouvel index tmp_index_{siteId} et l’index sur lequel se fait la recherche index_{siteId} . Après permutation, le nouvel index s’appelle index_{siteId} (la recherche pointe toujours sur ce nom) et le précédent index s’appelle maintenant tmp_index_{siteId} .
Suppression d’index
Et on supprime ensuite le précédent index avec la méthode deleteIndex(string $uid)du SDK qui appelle le endpoint DELETE /indexes/{uid} (avec l’uid tmp_index_{siteId}).
Recherche et résultats
Cette partie sera faite directement dans le front de notre application. Il s’agit d’un appel POST sur /indexes/{uid}/search avec en paramètres :
- q le(s) mot(s) recherché(s)
- filter avec un tableau de champs définis comme filtrable dans la configuration de l’index avec la valeur à filter pour chaque. Par exemple dans notre cas ["type"="article"] . Uniquement les documents de ce type seront retournés.
- facets avec un tableau de champs définis comme filtrable dans la configuration de l’index pour définir des facettes. Dans notre cas ["type"] .
- attributesToHighlight avec un tableau de champs. Le(s) mot(s) recherché(s) seront mis en avant dans les champs de résultats.
- les paramètres de pagination classiques page et hitsPerPage .
Il existe d’autres paramètres dont la liste est dans la documentation https://www.meilisearch.com/docs/reference/api/search#body
L’API retourne une liste de résultats au format suivant:
{
"hits": [
{
"id": "article_1",
"type": "article"
"title": "Le changement du climat",
"subtitle": null,
"date": null,
"text": "Texte à propos du changement climatique",
"url": "https://monsite.fr/le-changement-climatique",
"_formatted": {
"title": "Le changement du <em>climat</em>",
"subtitle": null,
"date": null,
"text": "Texte à propos du changement <em>climat</em>ique",
"url": "https://monsite.fr/le-changement-climatique",
"id": "article_1",
"type": "article"
}
},
...
],
"query": "climat",
"processingTimeMs": 15,
"hitsPerPage": 5,
"page": 1,
"totalPages": 2,
"totalHits": 10,
"facetDistribution": {
"type": {
"article": 1,
"video": 8,
"tweet": 1
}
},
"facetStats": {}
}
- les données de résultat et de pagination page, totalPage, hitsPerPage, totalHits .
- query le(s) mot(s) recherché(s).
- facetDistribution avec pour chaque facette le nombre de résultats.
- hits contient un tableau de résultats. Chacun contient les champs configurés au niveau de l’index pour être retourné. Le champs _formatted reprend ces champs mais avec les modifications pour mettre entre balise <em> les mots trouvés et sera donc utilisé pour le rendu front.
Meilisearch répond en quelques millisecondes. Un appel peut être effectué à chaque caractères saisi. C’est extrèmement fuilde et donne une bonne impresssion d’affinage des résultats au fur et à mesure de la saisie.
D’autres endpoints utiles
Health
Le endpoint GET /health permet de connaitre le statut de Meilisearch.
Nous l’avons utilisé dans une sonde de notre page de monitoring (via LiipMonitorBundle) pour avoir une alerte en cas d’indisponibilité de Meilisearch.
Metrics
Il y a un endpoint expérimental /metrics qui permettra de récupérer des statistiques :
- un compteur du nombre total d’appels
- un histogramme des temps de réponse
- une jauge de la taille de la base de données
- une jauge du nombre de documents indexés
- une jauge du nombre d’indexes
Conclusion
Meilisearch est donc une très bonne solution pour nous.
- toutes les fonctionnalités dont nous avions besoin.
- facile à mettre en place, avec un SDK simplifiant beaucoup son intégration dans notre application.
- très performant
- gratuit (pour la version open source)
Il suffit de bien se poser pour mettre en place un modèle de document correspondant à tous les types de contenus à indexer et configurer correctement notre index de manière à retourner les bons résultats en appliquant les bonnes règles sur les bons champs.
Il est sûrement possible d’aller beaucoup plus loin que notre simple recherche présentée ici en utilisant d’autres options décrites dans la documentation.
Si vous voulez mettre en place une recherche, c’est une solution à prendre en compte.
Optimiser l’expérience de recherche dans un projet Symfony multilingue : le choix de Meilisearch? was originally published in ekino-france on Medium, where people are continuing the conversation by highlighting and responding to this story.